



COMSOL在計(jì)算系統(tǒng)定義的函數(shù)時(shí)出錯(cuò)怎么解決(采用氣液屬性模塊生成的材料的屬性)?
MEMS微噴管流體仿真,工質(zhì)是水蒸氣與氧氣混合,采用氣液屬性模塊定義混合氣體,并生成材料,在此過程中自動(dòng)生成導(dǎo)熱系數(shù)、黏度等一系列函數(shù)。
3276 1 3
UmR_7347 ??? 4年前
COMSOL生成多孔材料的教程 
在COMSOL生成多孔材料可以采用CAD圖形導(dǎo)入的方式,在CAD內(nèi)生成多孔幾何模型后導(dǎo)入到COMSOL中進(jìn)行差集操作即可。CAD多孔模型的建立—以曲邊泰森多邊形為例1、設(shè)置好模型參數(shù)后運(yùn)行CAD_Voronoi圖 V2.1.exe可直接生成CAD圖,將無用的圖層刪除后,僅保留曲邊泰森多邊形圖像,并將CAD文件另存為.dxf格式文件備用。
5522 2 2
淵魚 ??? 4年前
使用 COMSOL 實(shí)現(xiàn)多物理場(chǎng)拓?fù)鋬?yōu)化的優(yōu)勢(shì) 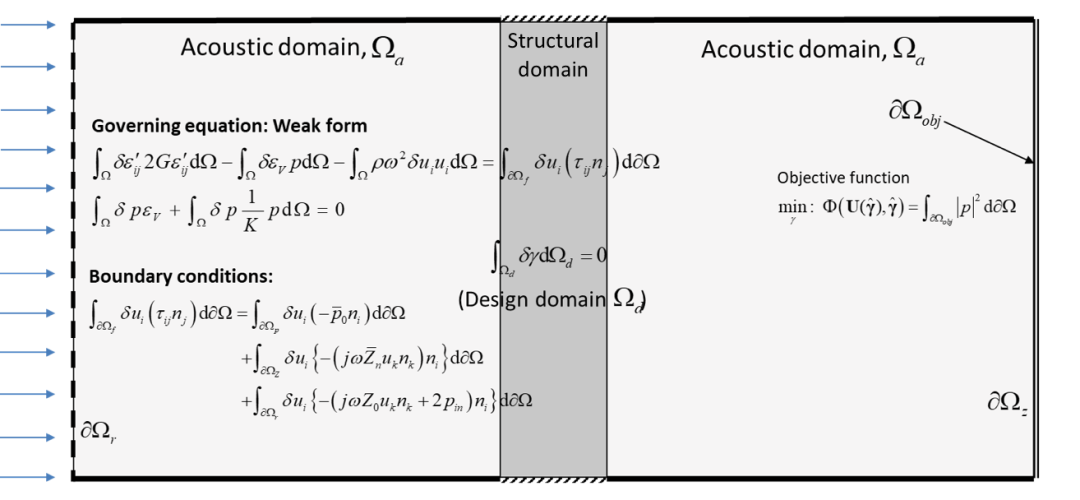
為拓?fù)鋬?yōu)化過程所需任務(wù)選擇的 COMSOL API 和 MATLAB? 代碼。COMSOL API 語(yǔ)法可以輕松方便地處理所需的任務(wù),無需多行復(fù)雜的代碼。設(shè)計(jì)變量的材料插值和參數(shù)化 拓?fù)鋬?yōu)化最終會(huì)在設(shè)計(jì)域中找到一種材料和另一種材料(或空隙)的最佳分布,用于優(yōu)化目標(biāo)函數(shù)。
3670 4 1
我是小能 ??? 3年前
如何在 COMSOL 中生成隨機(jī)表面 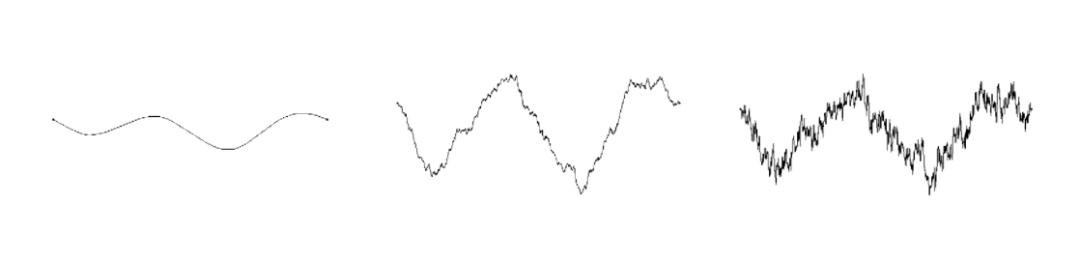
巖石裂隙流模型是 COMSOL Multiphysics案例庫(kù)中 的一個(gè)案例模型。基于文中描述的參數(shù)化表面,對(duì)兩個(gè)具有材料界面的 1 厘米大小的金屬塊進(jìn)行通用熱膨脹分析。底部材料板是鋁,頂部材料板是鋼。可視化圖顯示了材料界面和鋁板表面的 von Mises 應(yīng)力。
3462 10 2
我是小能 ??? 3年前
在 COMSOL 中模擬非線性磁性材料 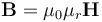
為了在頻域中求解,您需要一條“平均循環(huán)的”B-H/H-B 曲線,該曲線在特征頻率處近似于非線性材料。 有效非線性磁曲線計(jì)算器仿真 App 可生成用于頻域(時(shí)諧)仿真的有效 B-H/H-B 曲線。這些有效的 B-H/H-B 曲線可以直接在 COMSOL Multiphysics AC/DC 模塊的磁性接口中使用,該模塊內(nèi)置了對(duì)這些材料進(jìn)行建模的功能。
4135 6 5
我是小能 ??? 3年前
COMSOL多相流仿真方法 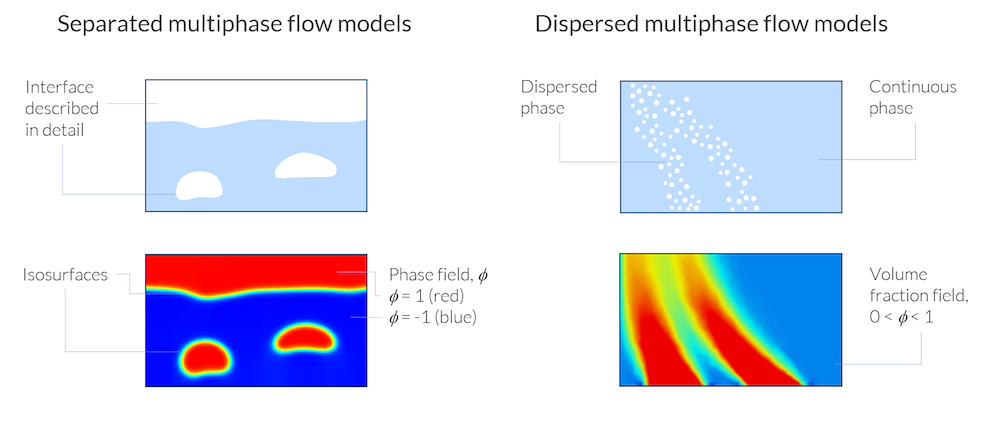
如果沒有計(jì)算能力的限制,表面追蹤方法將用于所有類型的混合。實(shí)際上,這些模型僅限于微流體以及黏性液體自由表面的研究。 分散多相流方法允許研究包含數(shù)以億計(jì)的氣泡、液滴或顆粒的系統(tǒng)。但是,即使是最簡(jiǎn)單的分散多相流模型,也可以生成非常復(fù)雜且要求很高的模型方程。上述幾種不同的模型非常適合描述特定的混合物,并能滿足工程師和科學(xué)家以相對(duì)較高的精度和合理的計(jì)算成本研究多相流的要求。
4755 8
學(xué)時(shí)習(xí) ??? 2年前
COMSOL代理模型加速仿真:從"小時(shí)級(jí)求解"到"毫秒級(jí)響應(yīng)"的工作站硬件配置分析 
若將隱藏層擴(kuò)展至 [8,256,256,128,128,64,6],權(quán)重參數(shù)激增,訓(xùn)練時(shí)需要將批量數(shù)據(jù)駐留顯存,24GB顯存是起步,48GB+才能從容混合精度訓(xùn)練:COMSOL 6.x版本支持FP16/FP32混合精度,NVIDIA RTX Pro系列(Ada/Blackwell架構(gòu))的Tensor Core可在此場(chǎng)景下提供2~4倍額外加速訓(xùn)練時(shí)間敏感性:對(duì)于1000樣本×8參數(shù)的數(shù)據(jù)集
1048
UltraLAB ??? 17天前
comsol中怎么生成白噪聲?
如題
1795 1
沉默是金_1896 ??? 4年前
comsol中壓電陶瓷仿真學(xué)習(xí)-材料篇 
-材料篇 因工作內(nèi)容改變,最近開始自學(xué)comsol,希望能從軟件小白的角度分享一些學(xué)習(xí)經(jīng)驗(yàn)。
3757 1
CAE備忘錄 ??? 3年前
如何在 COMSOL 中建立線性和非線性光學(xué)模型 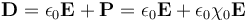
光學(xué)材料的三階磁化率 具有顯著三階磁化率的材料( )顯示出諸如光學(xué)克爾效應(yīng)、自相位調(diào)制、交叉相位調(diào)制、三次諧波生成和四波混頻等現(xiàn)象。為了說明 COMSOL Multiphysics 中的光學(xué)克爾效應(yīng) ,高強(qiáng)度(GW/cm2)單色光束(例如 Nd:YAG 激光源)通過由 BK-7 制成的非線性晶體傳播。
3826 1
我是小能 ??? 3年前
COMSOL晶體斷裂基于維諾圖Voronoi泰森多邊形建模 
在COMSOL中對(duì)兩種斷裂形式進(jìn)行模擬,模型采用Voronoi泰森多邊形構(gòu)建晶體的晶粒組織,幾何模型采用CAD Voronoi插件進(jìn)行參數(shù)化建模生成。插件采用合理的多邊形約束模式,可使得泰森多邊形晶粒結(jié)構(gòu)生成大小均勻,且可避免存在三角形晶體及角度過小的情況。模型對(duì)晶格及邊界分別定義不同的材料參數(shù),以實(shí)現(xiàn)開裂模式上的差異。
3195 10 6
淵魚 ??? 2年前
COMSOL隨機(jī)幾何分布合輯 
COMSOL隨機(jī)幾何分布合輯1、comsol with matlab 隨機(jī)幾何隨機(jī)圓隨機(jī)橢圓:2、COMSOL with Matlab連接 隨機(jī)裂縫生成3、matlab隨機(jī)生成橢圓裂隙導(dǎo)入comsol4、二維隨機(jī)裂隙-COMSOL5、如何用MATLAB生成隨機(jī)裂隙6、二維裂隙邊坡模型7、基于comsol的隨機(jī)分布顆粒模型建立方法
3610 4
燕子塢慕容復(fù) ??? 4年前
COMSOL和Matlab聯(lián)合仿真之復(fù)合材料填充建模 
另外,可以代碼可以自動(dòng)完成材料的設(shè)置、邊界條件的設(shè)置:方便進(jìn)行復(fù)合材料的力學(xué)性能、等效電導(dǎo)率、等效導(dǎo)熱系數(shù)等:可以批量生成模型,計(jì)算不同填料填充率時(shí),復(fù)合材料的物理性能:對(duì)于這些復(fù)合材料的仿真研究,既可以研究填充率的影響,也可以研究填料尺寸的影響、長(zhǎng)寬比比較大的材料取向的影響等。總之,隨機(jī)材料構(gòu)建的仿真模型給這類復(fù)合材料的研究提供了強(qiáng)大的理論研究手段。
3465 4 6
320科技工作室 ??? 3年前
COMSOL功能梯度材料中的光線反射 
本案例介紹在COMSOL建立功能梯度材料FGM幾何模型,并研究激光在通過梯度材料時(shí)的反射情況。 梯度材料模型采用CAD Voronoi FGM V1.0插件生成,CAD模型生成后只保留綠色圖層內(nèi)容作為梯度材料的反射界面。
2246 1
淵魚 ??? 1年前
用Python控制Comsol自動(dòng)運(yùn)行方法(三):構(gòu)建并訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)代理模型 
這種方法的優(yōu)勢(shì)在于: 自動(dòng)化:Python腳本簡(jiǎn)化了數(shù)據(jù)生成和模型訓(xùn)練流程; 高效性:DNN代理模型減少了對(duì)COMSOL仿真的依賴; 可擴(kuò)展性:適用于多種科學(xué)計(jì)算場(chǎng)景。具體案例接下來給大家展示一下如何用python控制一個(gè)1D鋰電池Comsol模型生成不同設(shè)計(jì)參數(shù)下電池性能的數(shù)據(jù)集,然后基于生成的數(shù)據(jù)集構(gòu)建并訓(xùn)練DNN代理模型。
3981
鋰電芯動(dòng) ??? 11月前

使用 COMSOL 仿真軟件模擬離心泵 
常見的離心泵模型需要使用動(dòng)網(wǎng)格,往往在模擬混合器從靜止?fàn)顟B(tài)切換到基本混合模式的“啟動(dòng)”階段上耗費(fèi)大量時(shí)間。凍結(jié)轉(zhuǎn)子方法假設(shè)泵的葉片相對(duì)于葉輪是凍結(jié)的,并且可向周圍區(qū)域施加離心力。它還可以良好地計(jì)算泵的擬穩(wěn)態(tài)條件。近似值可用作完整仿真的初始條件,借此計(jì)算出一段時(shí)間步的最終解。專門的 CFD 功能可以幫助用戶更輕松地求解復(fù)雜的離心泵模型。
2773 1
雙螺桿泵 ??? 2年前
COMSOL 顆粒增強(qiáng)復(fù)合材料力學(xué)仿真 
</p><p>顆粒增強(qiáng)復(fù)合材料作為一種新的結(jié)構(gòu)材料有著廣闊的發(fā)展前景。本篇文章采用COMSOL軟件對(duì)顆粒增加復(fù)合材料結(jié)構(gòu)進(jìn)行了參數(shù)化建模,并計(jì)算了添加顆粒后的壓縮變形性能。
5089 4 5
C乘風(fēng)破浪 ??? 4年前
如何在 COMSOL 中進(jìn)行粒子計(jì)數(shù) 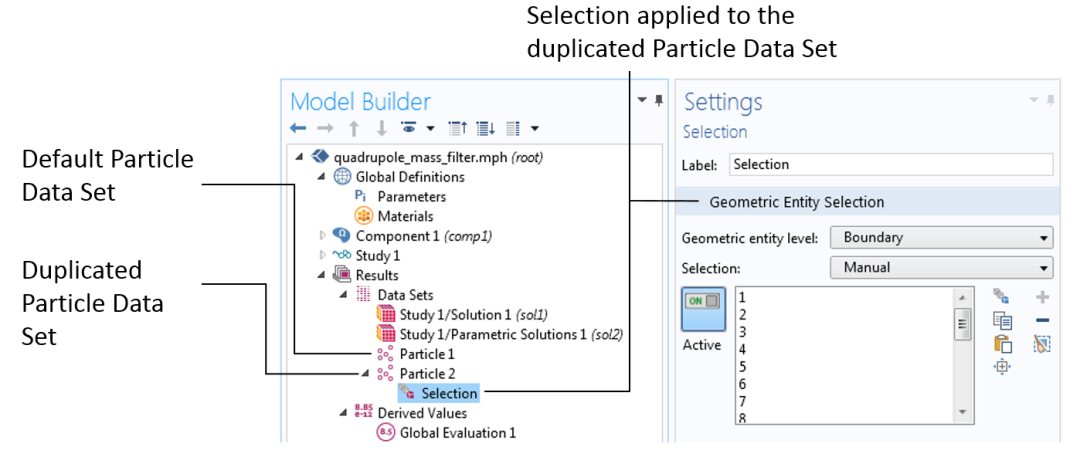
App 庫(kù)示例 粒子追蹤模塊 > 帶電粒子追蹤 > 敏感性高分辨率離子微探針 粒子追蹤模塊 > 教程 > 布朗運(yùn)動(dòng) 粒子追蹤模塊 > 流體流動(dòng) > 層流混合器COMSOL Multiphysics 中的粒子計(jì)數(shù)功能總結(jié)COMSOL 提供了三種方式來統(tǒng)計(jì)域和邊界中的粒子數(shù)。對(duì)只包含單個(gè)釋放特征的簡(jiǎn)單模型,可以直接使用后處理工具。
3223 7 1
我是小能 ??? 3年前
CAE云實(shí)證Vol.11:這樣跑COMSOL,是不是就可以發(fā)Nature了 
實(shí)證小結(jié)1、fastone平臺(tái)完美支持COMSOL的基于不同用戶策略的多機(jī)和多人并行,可大大提升任務(wù)效率;2、fastone支持搭建本地云端統(tǒng)一的混合云平臺(tái),完全不浪費(fèi)本地資源,本地資源不足時(shí)自動(dòng)溢出到云端,操作還簡(jiǎn)單,提高整體效率;3、fastone平臺(tái)提供獨(dú)占資源,絕不會(huì)被搶走,開放管理員權(quán)限,安全靈活;4、fasonte平臺(tái)環(huán)境完全自動(dòng)化配置,無需手動(dòng)維護(hù),省事
2542
fastone ??? 2年前
20條/頁(yè) 
 31
31 跳至頁(yè)

技術(shù)鄰APP
工程師必備
工程師必備
- 項(xiàng)目客服
- 培訓(xùn)客服
- 平臺(tái)客服
TOP
