



仿真干貨|算例核心數越多反而越慢?來了解下“最佳并行規模”! 
云端計算優化型實例:使用32、48、64、128、256核計算資源,耗時分別為662、458、375、299、321分鐘。注:云平臺資源充足,可同時進行多個作業的提交和計算,即耗時662分鐘得出所有結果(測試效率提升約64%),得出該作業最佳并行規模為128核。
2372
神工坊(高性能仿真) ??? 3月前
仿真干貨|算例核心數越多反而越慢?一篇文看懂“最佳并行規模” 
云端計算優化型實例:使用32、48、64、128、256核計算資源,耗時分別為662、458、375、299、321分鐘。注:云平臺資源充足,可同時進行多個作業的提交和計算,即耗時662分鐘得出所有結果(測試效率提升約64%),得出該作業最佳并行規模為128核。
875
神工坊(高性能仿真) ??? 1月前
Moldex3D模流分析之高效多核與并行計算技術 
Moldex3D高效多核與并行計算技術能降低您的成本并產生極高的效益。
1510
Moldex3D 中國 ??? 5月前
仿真干貨|算例核心數越多反而越慢?來了解下“最佳并行規模”! 
注:本地資源有限,無法提供更多資源測試,共進行了3次作業提交,總計耗時1826分鐘。云端計算優化型實例: 使用32、48、64、128、256核計算資源,耗時分別為662、458、375、299、321分鐘。 注:云平臺資源充足,可同時進行多個作業的提交和計算,即耗時662分鐘得出所有結果(測試效率提升約64%),得出該作業最佳并行規模為128核。
2710
神工坊(高性能仿真) ??? 1年前
[abaqus]多核并行運算報錯提問?
運算改成多核以后,每次運算一會兒就會停止運算,然后msg和dat文件無錯誤,log文件顯示以下報錯 Error: standard.exe / rank 0 / thread 7 encountered a system exception 0xC0000005 (EXCEPTION_ACCESS_VIOLATION)我看了內存是足夠的,請問有大佬能夠解答嗎
6052 9 10
我變成了光 ??? 3年前
ABAQUS三維銑削仿真-多核-并行運算 

ABAQUS 銑削 切削 多核運算 并行運算 Johnson-Cook模型 JC模型多核運算能充分利用電腦性能,加快運算效率。ABAQUS銑削仿真-三維立體方槽銑削仿真范例,視頻里面包含詳細的材料、分析步、接觸、邊界、加載、網格等參數設置。方槽的銑削分成了兩步,第一步鉆削,第二步向下銑削。介紹了銑削仿真的多核計算方法。
526 23
蕉大蕉 ??? 7年前
[Abaqus]黃永剛umat子程序多核并行運算報錯提問?
版本:Abaqus 2021問題:1、在Abaqus內導入inp文檔,調用原始的umat子程序huang.for后,多核運行成功。
4669 1 3
錢大寶 ??? 2年前
[Abaqus]黃永剛umat子程序多核并行運算報錯提問?
版本:Abaqus 2021問題:導入inp文檔,調用huang.for后,單核運行成功,多核運行報錯報錯:僅log文檔內存在—standard.exe / rank 0 / thread 4 encountered a system exception 0xC0000005 (EXCEPTION_ACCESS_VIOLATION)有大佬們能夠解答嗎?謝謝
2474 1
錢大寶 ??? 2年前
Abaqus & AMD,兼容和并行效率的那些事~ 
由于AMD平臺的核數一般較多,像我們使用的服務器采用AMD EPYC? 7002 Series雙路、128核。調度器默認肯定是用完一個節點,再用另一個節點。 這將導致災難式的結果——核越多越慢。這就好比花了更多的錢,得到了更差的服務 。 就看這個算例,用戶在單節點上使用64核相對8核多花將近10倍的錢。
3621
神工坊(高性能仿真) ??? 3年前
Abaqus并行效率二三事 
由于AMD平臺的核數一般較多,像我們使用的服務器采用AMD EPYC? 7002 Series雙路、128核。調度器默認肯定是用完一個節點,再用另一個節點。 這將導致災難式的結果——核越多越慢。這就好比花了更多的錢,得到了更差的服務 。 就看這個算例,用戶在單節點上使用64核相對8核多花將近10倍的錢。
4607 5 2
big膽! ??? 3年前
“神工坊”高性能工業仿真平臺|Fluent軟件并行效率測試 
表1 模型描述2、并行測試方案介紹 本次并行測試基于國家超算無錫中心高性能仿真計算集群進行,計算隊列每個節點包含2路12核E5-2680V3處理器,主頻2.5GHz,每個節點128GB DDR4內存。 測試時分別使用了單核,24核(一個節點),48核,72核,96核及120核進行計算。
2877 33 12
神工坊(高性能仿真) ??? 5年前
解密一顆芯片設計的全生命周期算力需求 
這套算法通過估算不同階段內、各個團隊所需的算力峰值之和,得出每階段的算力峰值。各團隊的峰值計算公式為每人每job峰值核數(多臺機器則為每臺核數*機器數)*團隊人數*每人job數(每個階段計算方式一致)。
2081
白話ic ??? 3年前
航空發動機360度整機數值模擬——超算助力工業仿真邁向系統級高保真時代 
我們對OpenFOAM的多個核心計算模塊進行了從核加速,覆蓋通量計算和代數求解,涉及大量計算熱點,熱點最高加速17倍,某風電場算例測試中OpenFAOM整體加速4倍。 2 AMI優化 結合“神威·太湖之光”超級計算機的硬件環境,優化AMI邊界處理的并行通信機制,將多個AMI的動態表面和靜態表面相結合,有效解決AMI的并行瓶頸。
2523
神工坊(高性能仿真) ??? 3年前
支持192核+4塊A100---2022年最強大AMD超算工作站GA660M上市 
圖靈超算工作站UltraLAB GA660M是2022年12月上市的一款配置雙AMD 第4代霄龍EPYC 9004處理器、24通道DDR5 4800內存、最高4塊A100/RTX4090系列GPU超算卡、內置海量并行存儲于一體、基于辦公靜音環境環境,這是目前為止CPU核數最多的(高達192核)、多核并行算力強大的圖形工作站技術特點: 支持2顆最新AMD 第4代EPYC(霄龍
2708
UltraLAB ??? 3年前
極大規模整車氣動數值模擬——構筑數字風洞基礎框架 
例如,本次汽車模擬算例就采用了7200核組(包含7200*64=46.08萬從核)。此外通過測試,發現7200核組相對3600核組,算例獲得了幾乎翻倍的性能,表明當前的算例大規模并行效率非常的優異。(3)求解器代碼精簡:求解器代碼精簡也是本應用的主要特色。此次求解器采用的LBM流場求解器只涉及幾百行代碼。
2447
神工坊(高性能仿真) ??? 3年前
在“神工坊”上使用OpenRadioss進行大規模并行仿真,效果如何? 
可以發現,“神工坊”高性能仿真平臺使用OpenRadioss進行并行仿真時,表現出了超高的計算效率。 從16核到128核,不同并行規模下,計算用時均明顯少于某仿真云平臺,加速比明顯高于某仿真云平臺 。且在“神工坊”高性能仿真平臺使用32核的計算速度就遠超某仿真云平臺使用64核甚至是128核的計算速度。
2517
神工坊(高性能仿真) ??? 3年前
智能駕駛域控制器SoC選型 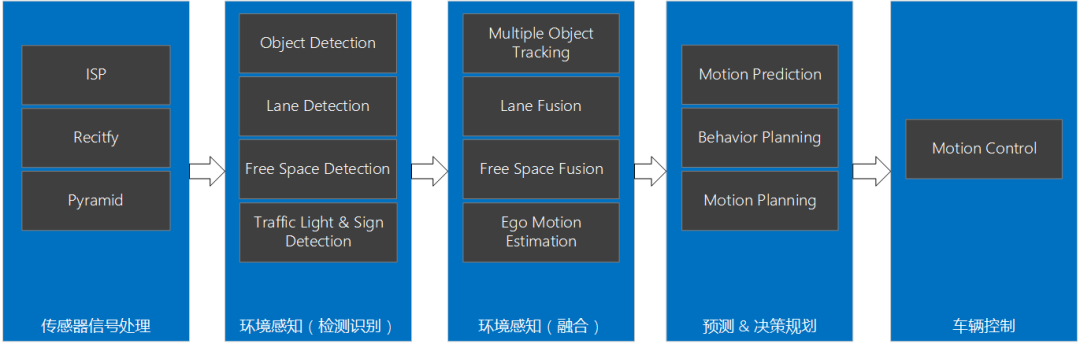
普通的GPU就包含了幾百個核,高端的有上萬個核,這對于處理大量的重復處理過程有著天生的優勢,同時更重要的是,它可以用來做大規模并行數據處理。
2769
駕駛哥 ??? 3年前
第一款96核4.8GHz--超頻工作站GR450P上市 
硬件特點:§ 采用AMD 銳龍TR PRO 7900WX/銳龍TR 7900X處理器,單CPU最大核數96個,三級緩存L3高達384MB,支持8個內存通道,其高主頻、大緩存、大內存帶寬特點,是目前單CPU多核并行算力的最強科學計算處理器。
2423 1 1
UltraLAB ??? 2年前
【仿真平臺性能測試】Fluent旋轉機械穩態分析 
“神工坊”秉持“算力賦能、協同創新”的理念,爭做“先進算力到仿真算能的轉換器”、“離散機理和垂直仿真場景的連接器”,助力我國工程仿真技術實現跨越發展,支撐重大裝備研制創新和工業設計研發數字化轉型。( 本文作者:郯俊建)
2846 1
神工坊(高性能仿真) ??? 3年前
COMSOL代理模型加速仿真:從"小時級求解"到"毫秒級響應"的工作站硬件配置分析 
一個中等規模多物理場模型(50萬網格)可能需要16GB內存,1000點掃描在10節點集群上并發,總內存需求即160GBCPU并行效率:COMSOL的FEM求解器對多核并行支持良好(PARDISO直接求解器、GMRES迭代求解器),但參數掃描的并行是"任務級"而非"線程級"——每個設計點內部用多核,多個設計點之間再并行,形成兩層并行結構I/O吞吐量:每個設計點產生的結果文件(mph、txt
1048
UltraLAB ??? 17天前
20條/頁 
 33
33 跳至頁

技術鄰APP
工程師必備
工程師必備
- 項目客服
- 培訓客服
- 平臺客服
TOP
