



ABAQUS并行計算CPU利用率低且不穩定,如何提升?
ABAQUS并行計算CPU利用率低且不穩定,設置30核心數并行計算,具體配置及CPU和內存利用率如下圖: 對比6核心,32G內存的筆記本工作站,同一模型(100萬四面體二階單元)計算時間只提升了1/3,感覺這配置效率有點低啊
3920 4 6
L_2194 ??? 3年前
abaqus多核計算CPU利用率?
為什么abaqus多線程計算時 顯示分析采用運動接觸法利用率上不去,罰接觸就可以。有什么辦法可以解決嗎?
2677 1
用點子智慧 ??? 3年前
智能駕駛域控制器SoC選型 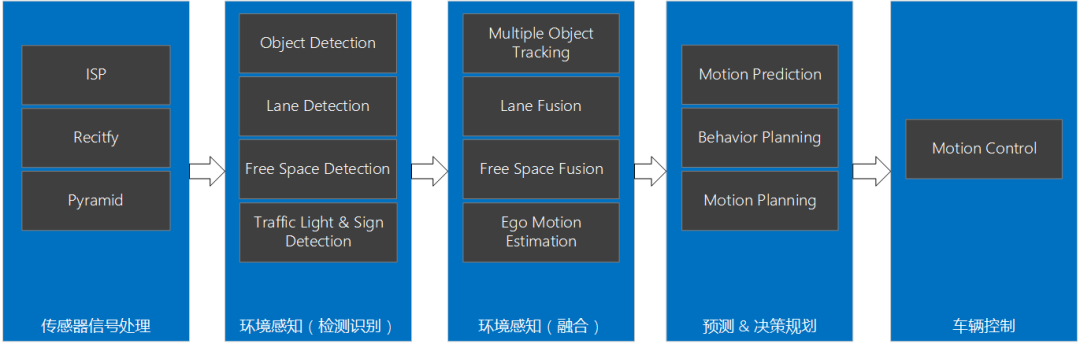
2.2 GPUCPU的功能模塊多,適合復雜的運算場景,大部分晶體管用在控制電路和存儲上,少部分用來完成運算工作。GPU的控制相對簡單,且不需要很大的Cache,大部分晶體管被用于運算,GPU的計算速度因此大增,擁有強大的浮點運算能力。CPU與GPU架構對比示意圖當前的多核CPU一般由4或6個核組成,以此模擬出8個或12個處理進程來運算。
2769
駕駛哥 ??? 3年前
【Abaqus電腦配置】CPU選Intel還是AMD? 
但是個人選購CPU,肯定是存在性價比問題,金錢開銷與性能提升倍數之間博弈的最佳核數是64,注意這里的提到的線程/核數通通指的是【物理核心】而不是【邏輯線程】,本文第二部分會解釋這一點。個人選購CPU用來跑Abaqus,建議至少4個物理核心,推薦8-32核,最好不要超過64核,因為非常不劃算。
9186 70 41
USim ??? 4年前
CPU工作原理:最簡單的元器件,構成了最復雜的運算 
的運算單元是由晶體管等各種基礎電子元件構成門電路,在由多個門電路組合成各種復雜運算的電路,在控制電路的控制信號的配合下完成運算,集成的電路單元越多,運算能力就越強。
2281
電子產品世界 ??? 4年前
CPU工作原理:最簡單的元器件,構成了最復雜的運算 
結 語 現在我們可以想到,CPU的運算單元是由晶體管等各種基礎電子元件構成門電路,在由多個門電路組合成各種復雜運算的電路,在控制電路的控制信號的配合下完成運算,集成的電路單元越多,運算能力就越強。
2143
凡億PCB ??? 4年前
【經驗貼】關于影響帶UMAT的ABAQUS模型計算速度的若干因素的探討
4、使用UMAT與否對運行效率的影響編寫了一個線彈性的UMAT,與使用ABAQUS自帶的線彈性材料屬性對比:核心數 位移U 時間 CPU利用率 使用UMAT與否8 0.5 3:35 100% 使用8 0.5 1:55 100% 未使用可見UMAT的使用會降低運算效率。
3098 2 1
EZABAQUS ??? 1年前
凌炫LE5039單路 XE5049雙路 EPYC 9754/9654/9554/9354工作站塔式服務器主機 仿真計算、HPC計算、有限元分析、CFD、ANSYS、CAE。 
硬件加速:支持自動OC超頻、IO高性能低延遲13. 軟件加速:可部署集群管理調度系統,支持橫向擴展;統一管理多節點,CPU平均使用率、內存平均使用率;監控集群作業運行狀態,顯示等待作業數、運行作業數、核時、在線用戶數,集群CPU總數等信息;資源監控:提供CPU平均利用率,內存平均利用率,磁盤IO速率等信息14.
2499 1
高性能工作站服務器 ??? 6月前
AMD EPYC 128核心256線程 CPU計算服務器/GPU服務器仿真計算、HPC計算、大數據分析、 
軟件加速:可部署集群管理調度系統,支持橫向擴展;統一管理多節點,CPU 平均使用 率、內存平均使用率;監控集群作業運行狀態,顯示等待作業數、運行作業數、核時、 在線用戶數,集群 CPU 總數等信息;資源監控:提供 CPU 平均利用率,內存平均利用 率,磁盤 IO 速率等信息 11. 操作系統:windows / linux 12.
2883
高性能工作站服務器 ??? 6月前
CAE/CFD云仿真免費試用│ LS-DYNA求解效率深度測評,六種規模,本地VS云端5種不同硬件配 
SMP版本是多個CPU之間共享相同的內存總線等資源,一般只能在單機上運行,受單機CPU性能及CPU核數限制。MPP版本是每個CPU有獨享的內存總線等資源,CPU之間通過網絡通信交換信息,可以在計算機集群上進行計算,大幅提升計算速度。單機和多機計算背后的詳細原理和意義在《 EDA云實證Vol.7:揭秘20000個VCS任務背后的“搬桌子”系列故事》里解釋得非常清楚。
3130 6 3
技術鄰公告 ??? 3年前
ABAQUS三維銑削仿真-多核-并行運算 

ABAQUS 銑削 切削 多核運算 并行運算 Johnson-Cook模型 JC模型多核運算能充分利用電腦性能,加快運算效率。ABAQUS銑削仿真-三維立體方槽銑削仿真范例,視頻里面包含詳細的材料、分析步、接觸、邊界、加載、網格等參數設置。方槽的銑削分成了兩步,第一步鉆削,第二步向下銑削。介紹了銑削仿真的多核計算方法。
526 23
蕉大蕉 ??? 7年前
支持192核+4塊A100---2022年最強大AMD超算工作站GA660M上市 
圖靈超算工作站UltraLAB GA660M是2022年12月上市的一款配置雙AMD 第4代霄龍EPYC 9004處理器、24通道DDR5 4800內存、最高4塊A100/RTX4090系列GPU超算卡、內置海量并行存儲于一體、基于辦公靜音環境環境,這是目前為止CPU核數最多的(高達192核)、多核并行算力強大的圖形工作站技術特點: 支持2顆最新AMD 第4代EPYC(霄龍
2708
UltraLAB ??? 3年前
被忽視的國之重器:高性能計算那些事兒 
高性能計算的工作原理在高性能計算中,處理信息的兩種主要方式為:串行處理,由中央處理器 (CPU) 完成。每個 CPU 核心通常每次只能處理一個任務。CPU 對于運行各種功能而言至關重要,如操作系統和基本應用程序(如文字處理、辦公生產力工具等)。并行處理,可利用多個 CPU 或圖形處理器 (GPU) 完成。GPU 最初是專為圖形處理而設計的。
2780
牛頓家的計算機 ??? 3年前
Comsol并沒有使用全部的物理內存就切換到了“核外模式”,影響運算速度。如何解決?
內存256G,只使用了90GB物理內存(圖2),就顯示切換“核外模式”,嚴重影響運算速度。2個CPU沒有共用整個256GB內存。相同模型,相同核心數量及插槽數,用正常服務器有限元矩陣分解環節使用了280多GB(圖1)。而我的服務器內存沒有得到充分利用。
3785 1 1
用戶_114148 ??? 10月前
自動駕駛系統設計的那些底層軟件開發中的重點解讀 
使用多核車規級CPU配置進行任務調度、執行自動駕駛相關的大部分核心算法,同時整合多源數據完成路徑規劃、決策控制等邏輯運算處理。
2496 1 1
駕駛哥 ??? 3年前
Moldex3D模流分析之計算機運算 
計算機運算工業CAE使用者的三個主要關注點是準確性、計算時間和易于使用。在現代模擬中,由于設計時間的幾何形狀日益復雜,對3D模擬的需求量很大,因此不可避免地會增加計算時間并需要更多的內存。對高精度和高性能計算的需求永遠不可低估。通常最新和更強大的CPU可以減少計算時間。然而,僅從CPU速率來看,這種改進在速度上都無法滿足工業使用者的需求。因此,利用多個多核CPU是最有效的方法。
2426
Moldex3D 中國 ??? 1年前
Abaqus并行效率二三事 
總結一下, 我認為本次效率提升有以下幾點原因: 1、模型被分解為多個Part,可以使得單元操作并行化; 2、全局矩陣求解分解為多個Part,充分發揮了單個節點的共享內存并行效率,規避了單節點大于16核之后共享內存并行效率低的問題; 3、神工坊集群具有現代化的HPC系統,集群計算機之間配備有Infiniband,提供了高帶寬、低延遲和可靠的數據交換
4607 5 2
big膽! ??? 3年前
CAE高性能計算的實踐經驗 
后續本人有嘗試用其他軟件解決能效核不運算的問題,但由于兩種核心的單核心運算速度不一,造成了用(8性能核+8能效核)分析反而比8性能核分析要慢。因此如果非專業者,建議使用服務器或11代前的酷睿CPU。 寫在最后這篇文章雖然不是射出模具相關知識,但卻是讓很多CAE使用者都頭痛過的問題。花了大價格配置的服務器,結果分析速度提升不明顯。或用多核心分析低網格的項目,資源分配不合理。
2656
ACMT協會 ??? 2年前
Abaqus & AMD,兼容和并行效率的那些事~ 
總結一下, 我認為本次效率提升有以下幾點原因: 1、模型被分解為多個Part,可以使得單元操作并行化; 2、全局矩陣求解分解為多個Part,充分發揮了單個節點的共享內存并行效率,規避了單節點大于16核之后共享內存并行效率低的問題; 3、神工坊集群具有現代化的HPC系統,集群計算機之間配備有Infiniband,提供了高帶寬、低延遲和可靠的數據交換
3621
神工坊(高性能仿真) ??? 3年前
高性能計算:RoCE v2 vs. InfiniBand網絡該怎么選? 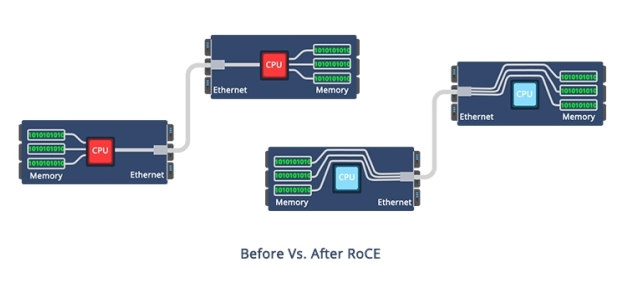
RoCE 規范在以太網上實現了 RDMA 功能,ROCE 需要無損網絡,RoCE的主要優勢在于它的延遲較低,因此可提高網絡利用率;同時它可避開TCP/IP 并采用硬件卸載,因此 CPU 利用率也較低。新 RoCEv2 標準可實現 RDMA 路由在第三層以太網網絡中的傳輸。RoCEv2 規范將用以太網鏈路層上的 IP 報頭和 UDP 報頭替代 InfiniBand 網絡層。
3363
牛頓家的計算機 ??? 3年前
20條/頁 
 27
27 跳至頁

技術鄰APP
工程師必備
工程師必備
- 項目客服
- 培訓客服
- 平臺客服
TOP
