



Lumerical案例 | 獲得理想FDTD性能 
正如我們在步驟1中看到的,核心數增加4倍并不會帶來4倍的性能提升。如果使用四分之一的可用核心并行運行4個仿真,那么在很多情況下,其速度會比使用所有核心順序運行4個仿真更快。在下圖中,我們使用了所有可用核心,但通過增加容量并相應減少每次模擬的核心數來實現性能提升。示例腳本FDTD_bench_capacity.lsf包含在內。
1240
摩爾芯創 ??? 28天前
Moldex3D模流分析之多CPU和叢集式計算機計算 
計算速度可以被更新更強大的CPU改善。然而,僅僅改進CPU的速度在速度和準確性上并無法滿足工業用戶。多核心CPU計算機組成的使用,便成為可行的解決方案。效能顯著的案例探討Moldex3D身為CAE專業廠商,是市面上能完整支持全并行計算的模流軟件,包含流動、保壓、冷卻、翹曲、纖維、多材質射出等分析。
1921
Moldex3D 中國 ??? 5月前
AMD EPYC 128核心256線程 CPU計算服務器/GPU服務器仿真計算、HPC計算、大數據分析、 
適用場景: CAE/仿真計算: 如Fluent, Abaqus, ANSYS等,能極大縮短求解時間。 大數據與數據分析: 海量內存和多核心能輕松處理TB級數據集。 人工智能與機器學習: 適合模型訓練和推理,尤其適合中等規模或作為大型集群的一個計算節點。 科研計算: 在物理、化學、生物、氣象等領域進行復雜的數值模擬。
2883
高性能工作站服務器 ??? 6月前
結構力學分析(靜力、動力、疲勞)、多體系統仿真、鑄造/成型過程模擬算法分析,及工作站硬件配置推薦 
MBD CPU是第一優先級: 推薦高主頻、多核心的CPU。
2842
UltraLAB ??? 6月前
汽車NVH及安全控制國家重點實驗室的計算利器---高速計算設備硬件配置推薦 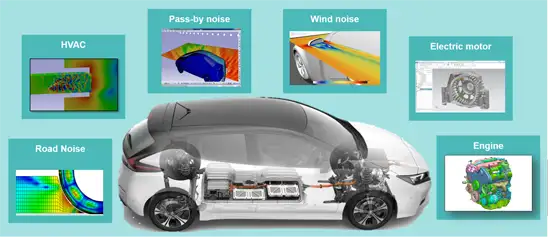
為了加速Adams/Car的計算,可以考慮以下配置:§ CPU:選擇高性能的多核心CPU,以提高計算效率和并行計算能力。一般來說,對于較小和簡單的模型,使用2到4個核心可能已經足夠快速地完成仿真。但對于較大和復雜的模型,通常建議使用8個或更多核心以獲得更好的并行計算性能。并行計算并不是線性的,即使增加了更多的核心,也不一定能夠線性提高計算速度。
2345 1
UltraLAB ??? 2年前
智能駕駛域控制器SoC選型 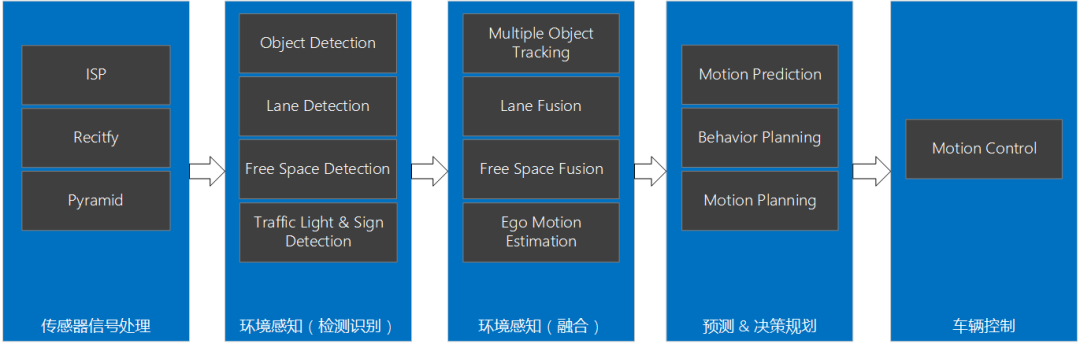
NN算力的增加,意味著需要處理更多的傳感器、更高分辨率的相機、更豐富的場景、更復雜的功能。相應的,ACPU算力需求也會增加,以支持更多更高分辨率傳感器數據的預處理、深度學習模型的前后處理、更復雜的感知融合功能、軌跡預測和行為規劃、影子模式數據挖掘功能等。綜上,ACPU的選型需要重點關注算力,同時需要留意外設和操作系統的功能安全級別。
2769
駕駛哥 ??? 3年前
Ansys Fluent:CFD 創新史 
1980 年代初期,在謝菲爾德大學大樓的多位人士的貢獻下,Ansys Fluent成為第一個具有圖形用戶界面和工作流程而非命令行輸入的商業計算流體動力學 (CFD) 軟件。隨著它在行業中的采用,Fluent 的受歡迎程度逐年增加。2006 年 5 月,Fluent Inc. 被 Ansys 收購。
3586
福祿恩特 ??? 3年前
ANSYS加速仿真計算硬件配置建議 
雖然高時鐘頻率的處理器通常是理想之選,但對于運行在大型集群上的 Ansys 應用(例如 Ansys CFX、Fluent 和 LS-DYNA)而言,其重要性并非那么突出。在大型集群中,通信吞吐量比計算速度更為重要,因此處理器速度并非那么關鍵。通常不建議選擇核心數最多的處理器,因為如果CPU內存沒有相應增加,可能會對內存帶寬產生負面影響。
4137
UltraLAB ??? 5月前
航空航天領域的飛行器氣動設計、結構強度與疲勞、燃燒與傳熱、電磁散射(隱身)、軌道動力學 算法特點,及圖形工作站硬件配置推薦 
CPU多核是第二優先級: 搭配高核心數的CPU(如AMD Threadripper),用于前處理、后處理以及GPU無法完全覆蓋的計算部分。內存容量要巨大: 256GB是推薦起點,根據模型規模可配置512GB或更多。結構/軌道動力學客戶: 均衡的CPU是關鍵: 推薦高主頻、多核心的CPU。AMD Ryzen 9或Intel Core i9的旗艦型號是性價比很高的選擇。
3993
UltraLAB ??? 6月前
Ansys 2025 R1 | 以強大數字工程技術增強協作,拓展云計算及AI并賦能數據洞察 
在不影響整體仿真速度的情況下,設計人員可以添加更多參數,優化精度 CFD HPC Ultimate 是一款全新的產品,可在多個 CPU 內核或 GPU 上針對一項任務實現企業級 CFD 功能(不限計算核心的 CFD 分析),而無需額外的 HPC 許可證 Ansys Lumerical FDTD? 高級 3D 電磁仿真軟件支持全新 GPU 加速仿真,與使用 CPU 相比,所需內存減少了50%
3369
宇熠科技 ??? 1年前
Moldex3D模流分析之高效多核與并行計算技術 
計算速度可以被更新更強大的CPU改善。然而,僅僅改進CPU的速度在速度和準確性上并無法滿足工業用戶。多核心CPU計算機組成的使用,便成為可行的解決方案。效能顯著的案例探討Moldex3D身為CAE專業廠商,是市面上能完整支持全并行計算的模流軟件,包含流動、保壓、冷卻、翹曲、纖維、多材質射出等分析。
1510
Moldex3D 中國 ??? 5月前
一文讀懂Fluent并行計算,三大技術提升計算效率新境界! 
我們發現,8線程下的計算耗時優于16線程,這可能是因為16線程CPU多核心之間通信時間增加導致整體效率下降。綜合以上來看,最佳計算線程數應在12左右。CPU線程數并非越多越好,它存在最優線程數,相關文獻已對此進行研究[2]。
3975
神工坊(高性能仿真) ??? 2年前
GPU引領CAE仿真算力革命 
傳統的CAE仿真主要依賴于CPU計算,在處理大規模復雜模型時往往會遭遇性能瓶頸,導致仿真時間過長,難以滿足快速迭代設計的需求。隨著產品設計復雜性的不斷增加,企業對CAE仿真的計算效率提出了更高要求。“軟件跟著硬件走。”CAE通過在將模型離散成網格進行仿真計算,網格越密集,仿真結果越可靠,這意味著CAE天然適合進行大規模并行計算任務,這與GPU強大的并行計算能力高度契合。
2425 1
仿真APP ??? 1年前
磁學國家重點實驗室的計算利器---高速計算設備硬件配置推薦 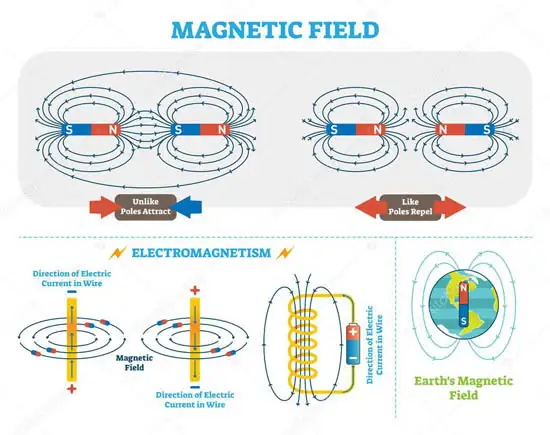
計算瓶頸:在使用OOMMF進行仿真時,計算瓶頸通常出現在模型復雜度較高、網格數量較多或者時間步長較小的情況下。此時,計算時間可能會顯著增加。為了加速OOMMF的計算,可以考慮以下配置方面的改進:使用多核處理器或具有更高核心數的CPU。增加內存容量以容納大型模型和復雜的仿真。使用高速硬盤,如固態硬盤(SSD),以提高數據讀寫速度。
2427
UltraLAB ??? 2年前
Intel和AMD展示:芯片的兩條路 
酷睿i9 12900K搭載了一顆共16核、8個高性能核心和8個高效能核心的CPU,GPU為“UHD770”,而酷睿i9 13900K隨著CPU架構的更新,效率更高核心數翻了一番,達到16個核心。“Intel 7”(10nm)用于制造。
2559
第三代半導體聯合創新孵化中心 ??? 3年前
臺積電先進制程和封裝的更多細節 
AMD、AWS 和 NVIDIA 等半導體設計公司正在使用 3DFabric 聯盟,隨著 2D、2.5D 和 3D 封裝的使用吸引了更多的產品創意,這個數字只會隨著時間的推移而增加。臺積電擁有世界一流的DTCO工程團隊,國際競爭足以讓他們不斷創新新業務。數字、模擬和汽車細分市場將受益于臺積電在 FinFlex 上宣布的技術路線圖選擇。
2313
平頭叔 ??? 3年前
一期一會 | 光線追跡在光學和光子組件設計中的應用 
高端CPU有多個內核,其中最高端的CPU有多達128個內核,其可獨立處理每束光線。然而,GPU(通常稱為顯卡)具有不同的架構,其內部的計算單元更小但更多。因此,更好的GPU可以提高光線追跡功能。NVIDIA在2018年將RTX技術推向市場以來,GPU的功能得到了顯著提升。這些GPU包含光線追跡內核(RT內核),是專門用于優化光線傳播的計算單元。為光線追跡提供專用計算單元,可實現更高的性能。
2383
Ansys中國 ??? 1月前
【Abaqus電腦配置】CPU選Intel還是AMD? 
比如散熱系統將直接決定CPU是否降頻,高功率CPU建議用水冷系統效果會更好;再比如搭建Custer服務器集群時,隨著CPU數量和MPI等級的增加,需要更多的MPI通信,具有更高帶寬和更低延遲的互連通常將允許更大的性能擴展和更高的CPU限制,由于延遲顯著降低,使用Infiniband互連通常比10Gb以太網性能更好。
9186 70 41
USim ??? 4年前
ZEMAX軟件技術應用專題:關于Opticstudio選用核數跟優化速度的關系 
在計算方面,更多的內核并不意味著更快的計算。這取決于你在做什么樣的計算。 如果計算不需要這么多的資源,而且核心/線程的數量超過了需要,那么將數據分配給每個線程的時間會更長。您可以設置OpticStudio在計算過程中可以使用的內核數量。 然而,如上所述,你將只得到所要求的一部分資源。有一個平行計算的理論叫做阿姆達爾定律。 X軸代表處理器的數量。
2502
w**elab86_Swsp ??? 3年前
車規級MCU芯片介紹 
未來,隨著汽車智能化程度的不斷增加,車規級MCU將向多功能集成及超低功耗方向發展,且使用數量將不斷增加;同時,大量使用的車載傳感器、車載攝像頭,也需要高性能的MCU來做模擬數據的運算處理與驅動控制。因此,在未來更高階自動駕駛等級的汽車中,加以多傳感器融合的大趨勢下,32位車規級MCU將成為主流產品。
5309 7 4
圖元TOPBRAIN ??? 3年前
20條/頁 
 19
19 跳至頁

技術鄰APP
工程師必備
工程師必備
- 項目客服
- 培訓客服
- 平臺客服
TOP
