



yolov7-pytorch可用于訓練自己的數據集 
訓練步驟a、訓練VOC07+12數據集數據集的準備本文使用VOC格式進行訓練,訓練前需要下載好VOC07+12的數據集,解壓后放在根目錄數據集的處理修改voc_annotation.py里面的annotation_mode=2,運行voc_annotation.py生成根目錄下的2007_train.txt和2007_val.txt。
2280
機器學習AI算法工程 ??? 3年前
SimData:基于aiSim的高保真虛擬數據集生成方案 
一、前言在自動駕駛感知系統的研發過程中,模型的性能高度依賴于大規模、高質量的感知數據集。目前業界常用的數據集包括 KITTI、nuScenes、Waymo Open Dataset 等,它們為自動駕駛算法的發展奠定了重要基礎。
2375
康謀keymotek ??? 6月前
工業仿真的基礎數據庫:Granta數據集 
<p>10月28日,Ansys官方『工業仿真的基礎數據庫:Granta數據集』研討會為您展開介紹Granta數據集在材料數據整合、材料屬性分析、智能推薦加速選材決策等等,感興趣的下滑預約學習??</p><p><br></p><p><br></p><figure style="text-align: center;" class="ql-align-center">
<figure class=
2457 1
技術鄰公告 ??? 6月前
SimData深度解析:高保真虛擬數據集的構建與評測 
文章中,簡單介紹了一下SimData數據集情況,本文將深度解析該SimData自動駕駛虛擬數據集——由aiSim仿真平臺構建,從數據生產工具鏈、數據集結構到基于BEVFormer的深度評測,全方位展示高保真合成數據的應用價值。一、 從仿真到標準格式的工具鏈虛擬數據要真正落地,首要解決的是與現有主流數據格式的兼容性。
2269
康謀keymotek ??? 5月前
直播預告 | 基于VTD的Lidar訓練數據集構建方案分享 
本期海克斯康直播講堂請到了自動駕駛仿真專家葉立斌老師為我們帶來基于VTD的Lidar數據集構建方案,從激光雷達物理建模到數據集獲取方案,為我們帶來高質量數據獲取的最新方法,敬請關注!
2250
海克斯康設計與仿真 ??? 1年前
【發個廣告】工程車車牌數據集1|純圖片|1000+張 
最近搗鼓一個數據集的公眾號,提供數據集出售、咨詢等,985算法團隊???</p><p>各位老板有需要可以關注下公眾號</p><div contenteditable="false" width="100%"><figure class="figure-link" data-title="編程貓的算法屋" data-link="https://i-blog.csdnimg.cn/direct/c7eda8cefa934b5f8e201e5d75a28ba7
2091
上吧皮卡丘 ??? 6月前
3D目標檢測/點云/遙感數據集匯總 
DOTA數據集(images) 數據集是遙感圖像,DOTA1.5是在DOTA基礎上擴增的數據集 DOTA數據集包含2806張航空圖像,尺寸大約為4kx4k,包含15個類別共計188282個實例。
4321 1 1
駕駛哥 ??? 4年前
Updated---邊坡穩定性概率分析數據集(Probabilistic Approach) 
在過去三年的邊坡工程課程教學中,逐漸進化出一個完善的邊坡穩定性概率分析數據集,包括多種先進的計算工具。
3232
計算巖土力學 ??? 4年前
人工神經網絡(Artificial Neural Networks,簡稱ANNs)-2、3 
模糊集被編碼為網絡層之間的連接權重,這提供了處理和訓練模型的功能。
2245 1
仿真資料吧 ??? 1年前
人工神經網絡(ANN)(網絡架構)-4
人工神經網絡(ANN)(網絡架構)-4 人工神經網絡(ANN):這是一種受人腦啟發的信息處理范式。ANN通過示例學習,就像人類一樣。通過學習過程,ANN可以被配置用于特定應用,如模式識別或數據分類。學習過程主要涉及調整神經元之間的突觸連接。 ANN的類型: ANN有多種架構,每種架構都有其優勢和劣勢。
2538 2 1
仿真資料吧 ??? 1年前
人工神經網絡(Artificial Neural Networks,簡稱ANNs)-1 
ANN用于目標函數輸出可能是離散值、實值或多個實值或離散值向量的問題。ANN學習方法對訓練數據中的噪聲非常魯棒。訓練示例可能包含錯誤,但這不會影響最終輸出。通常在需要快速評估學習目標函數的情況下使用ANN。ANN可以承受長時間的訓練,這取決于網絡中的權重數量、考慮的訓練示例數量以及各種學習算法參數的設置。
2544 1 1
仿真資料吧 ??? 1年前
語音識別系列之脈沖神經網絡特征工程 
(2)人工耳蝸物理轉錄 人工耳蝸可作為動態音頻傳感器(Dynamic Audio Sensor, DAS),記錄人工耳蝸對音頻數據的響應,將TIDIGITS音頻數據集轉錄為N-TIDIGITS脈沖數據集[8]。
2463
聲學工程師小吳 ??? 3年前
深度學習|會開發AI的AI:超網絡有望讓深度學習大眾化 
用圖來表示神經網絡為此,你得訓練數據——在本案例中,數據就是可能的人工神經網絡(ANN)結構的隨機樣本。對于樣本的每一個結構,你都要從圖開始,然后用圖超網絡來預測參數,并利用預測的參數對候選 ANN進行初始化。然后該ANN會執行一些特定任務,如識別一張圖像。通過計算該ANN的損失函數來更新做出預測的超網絡的參數,而不是更新該ANN的參數以便做出更好的預測。這樣以來,該超網絡下一次就能做得更好。
2115 2
龍騰AI技術 ??? 3年前
人工神經網絡(Artificial Neural Networks,簡稱ANNs)-Python中實現人工神經網絡訓練過程 
<p class="ql-align-center"><br></p><p>人工神經網絡(ANN)是一種受大腦啟發的信息處理模式。就像人類一樣,ANN通過示例來學習。通過學習過程,ANN被配置用于特定應用,例如模式識別或數據分類。學習過程主要涉及調整神經元之間存在的突觸連接。
2448 1
仿真資料吧 ??? 1年前
人工神經網絡及其應用 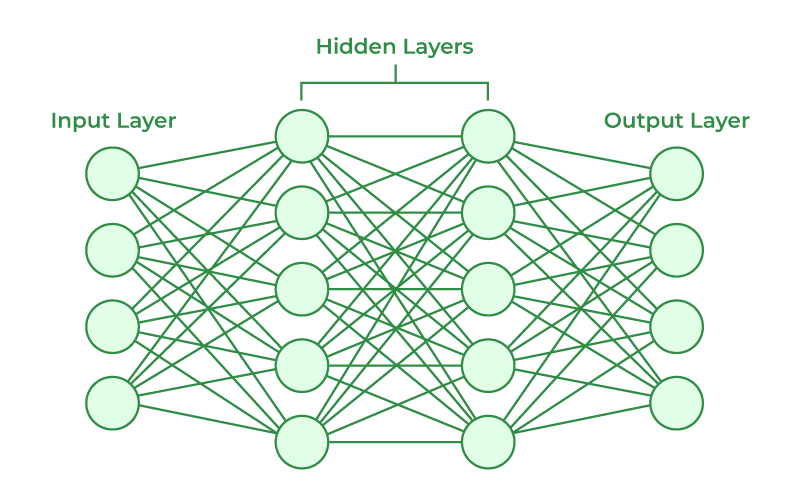
人工神經網絡使用訓練集進行訓練。例如,假設您要教 ANN 識別貓。然后,它會顯示數千張不同的貓圖像,以便網絡可以學習識別貓。一旦使用貓的圖像對神經網絡進行了足夠的訓練,那么您需要檢查它是否可以正確識別貓圖像。這是通過使 ANN 通過確定它們是否是貓圖像來對它提供的圖像進行分類來完成的。ANN 獲得的輸出由人類提供的關于圖像是否為貓圖像的描述得到證實。
2574
仿真資料吧 ??? 1年前
基于深度學習的可解釋特征準確預測混凝土抗壓強度 
從文獻中收集的數據集被分成兩個子數據集——80% 作為訓練集,20% 作為測試集——分別用于訓練和測試 CNN 模型。實驗收集的數據包括 16 組再生骨料混凝土配合比、16 組常規混凝土和 16 組從其他實驗室獲得的高強混凝土。這部分數據表示為實驗集,用于評估通過文獻數據訓練和測試的不同模型的穩健性。
2776 6 1
龍騰AI技術 ??? 3年前
訓練集和測試集的分布差距太大有好的處理方法嗎? 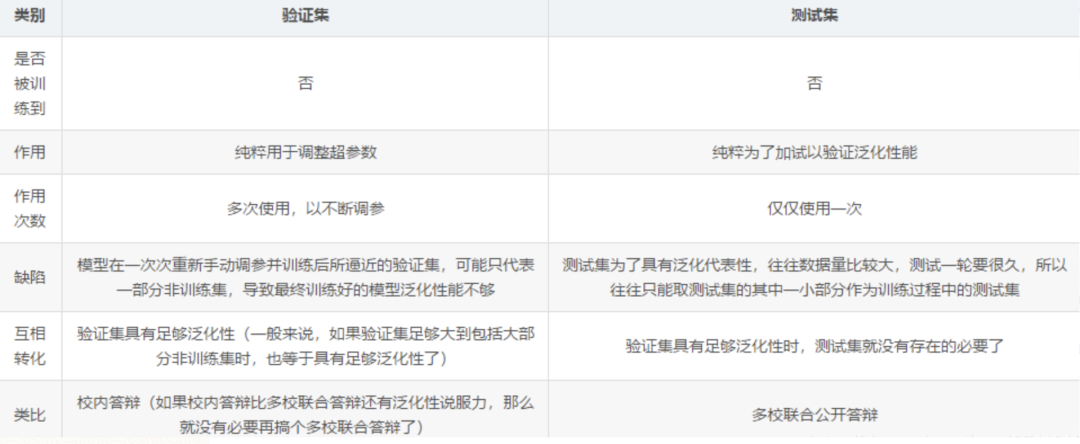
因此在分配訓練集和測試集的時候,如果測試集的數據越小,對模型的泛化誤差的估計將會越不準確。所以需要在劃分數據集的時候進行權衡。測試集的比例訓練集數據的數量一般占2/3到4/5。在實際應用中,基于整個數據集數據的大小,訓練集數據和測試集數據的劃分比例可以是6:4、7:3或8:2。對于龐大的數據可以使用9:1,甚至是99:1。具體根據測試集的劃分方法有所不同。
3076
牛頓家的計算機 ??? 3年前
IJP:從RVE到組件的跨尺度預測 
如果FEM預測范圍超出了ANN預測范圍,將使用CACPFEM模型生成更多變形條件下的數據樣本,并添加到數據庫中。將使用更新的數據庫重新訓練ANN模型,并且將再次重新檢查優化A和B的必要性。優化B的循環將繼續,直到最終FEM預測范圍在ANN預測范圍內。優化C:跨尺度比較的優化。如果FEM預測的范圍在ANN預測的范圍內,有關地區的形變信息將作為微尺度預測的邊界條件應用于RVE。
3228
CPFEM工作室 ??? 3年前
前瞻技術|從物理性質逆推分子結構 
首先,基于1297組數據集訓練分子結構和物理性質之間的關系。圖1展示的是測試過程中使用的分配系數。 圖1. mol-infer的訓練數據集和目標性質(分配系數=10.0) 其次,使用MILP執行逆運算。設目標分配系數為10.0,生成種子分子的圖結構和對應官能團的樹結構(見圖2),用來預測分子結構。
1894
上海庭田信息科技有限公司 ??? 3年前
數據挖掘中的數據預處理 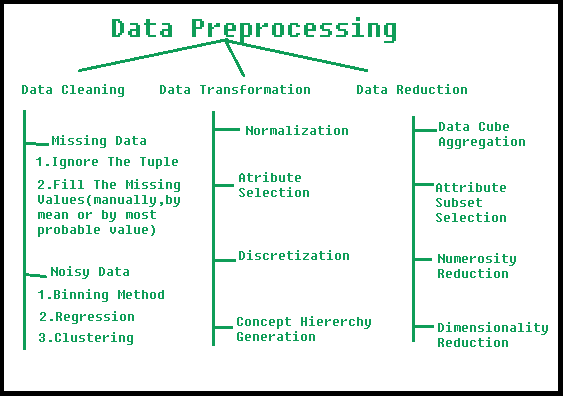
聚類通常用于通過將相似的數據點替換為具有代表性的質心來減小數據集的大小。可以使用 k-means、分層聚類和基于密度的聚類等技術來完成此操作。 壓縮:這涉及在保留重要信息的同時壓縮數據集。壓縮通常用于減小數據集的大小,以便進行存儲和傳輸。可以使用小波壓縮、JPEG 壓縮和 gif 壓縮等技術來完成。如何使用數據預處理?
2546
仿真資料吧 ??? 1年前
20條/頁 
 76
76 跳至頁

技術鄰APP
工程師必備
工程師必備
- 項目客服
- 培訓客服
- 平臺客服
TOP
