數(shù)據(jù)挖掘中的數(shù)據(jù)預(yù)處理

數(shù)據(jù)預(yù)處理是數(shù)據(jù)挖掘過(guò)程中的一個(gè)重要步驟。它是指清理、轉(zhuǎn)換和集成數(shù)據(jù),以便為分析做好準(zhǔn)備。數(shù)據(jù)預(yù)處理的目標(biāo)是提高數(shù)據(jù)質(zhì)量,使其更適合特定的數(shù)據(jù)挖掘任務(wù)。
數(shù)據(jù)預(yù)處理步驟
數(shù)據(jù)預(yù)處理是數(shù)據(jù)挖掘過(guò)程中的一個(gè)重要步驟,涉及清理和轉(zhuǎn)換原始數(shù)據(jù)以使其適合分析。數(shù)據(jù)預(yù)處理中的一些常見(jiàn)步驟包括:
- 數(shù)據(jù)清理:這涉及識(shí)別和糾正數(shù)據(jù)中的錯(cuò)誤或不一致,例如缺失值、異常值和重復(fù)項(xiàng)。可以使用各種技術(shù)進(jìn)行數(shù)據(jù)清理,例如插補(bǔ)、刪除和轉(zhuǎn)換。
- 數(shù)據(jù)集成:這涉及組合來(lái)自多個(gè)來(lái)源的數(shù)據(jù)以創(chuàng)建統(tǒng)一的數(shù)據(jù)集。數(shù)據(jù)集成可能具有挑戰(zhàn)性,因?yàn)樗枰幚砭哂胁煌袷健⒔Y(jié)構(gòu)和語(yǔ)義的數(shù)據(jù)。可以使用記錄鏈接和數(shù)據(jù)融合等技術(shù)進(jìn)行數(shù)據(jù)集成。
- 數(shù)據(jù)轉(zhuǎn)換:這涉及將數(shù)據(jù)轉(zhuǎn)換為合適的格式以供分析。數(shù)據(jù)轉(zhuǎn)換中使用的常見(jiàn)技術(shù)包括規(guī)范化、標(biāo)準(zhǔn)化和離散化。標(biāo)準(zhǔn)化用于將數(shù)據(jù)縮放到公共范圍,而標(biāo)準(zhǔn)化用于將數(shù)據(jù)轉(zhuǎn)換為零均值和單位方差。離散化用于將連續(xù)數(shù)據(jù)轉(zhuǎn)換為離散類(lèi)別。
- 數(shù)據(jù)縮減:這涉及在保留重要信息的同時(shí)減小數(shù)據(jù)集的大小。可以通過(guò)特征選擇和特征提取等技術(shù)實(shí)現(xiàn)數(shù)據(jù)縮減。特征選擇涉及從數(shù)據(jù)集中選擇相關(guān)特征的子集,而特征提取涉及將數(shù)據(jù)轉(zhuǎn)換為較低維空間,同時(shí)保留重要信息。
- 數(shù)據(jù)離散化:這涉及將連續(xù)數(shù)據(jù)劃分為離散的類(lèi)別或間隔。離散化通常用于需要分類(lèi)數(shù)據(jù)的數(shù)據(jù)挖掘和機(jī)器學(xué)習(xí)算法。離散化可以通過(guò)等寬分箱、等頻分箱和聚類(lèi)等技術(shù)來(lái)實(shí)現(xiàn)。
- 數(shù)據(jù)規(guī)范化:這涉及將數(shù)據(jù)縮放到一個(gè)通用范圍,例如介于 0 和 1 之間或 -1 和 1 之間。歸一化通常用于處理具有不同單位和尺度的數(shù)據(jù)。常見(jiàn)的規(guī)范化技術(shù)包括最小-最大規(guī)范化、z 分?jǐn)?shù)規(guī)范化和十進(jìn)制縮放。
數(shù)據(jù)預(yù)處理在保證數(shù)據(jù)質(zhì)量和分析結(jié)果的準(zhǔn)確性方面起著至關(guān)重要的作用。數(shù)據(jù)預(yù)處理中涉及的具體步驟可能因數(shù)據(jù)的性質(zhì)和分析目標(biāo)而異。
通過(guò)執(zhí)行這些步驟,數(shù)據(jù)挖掘過(guò)程變得更加高效,結(jié)果也變得更加準(zhǔn)確。
數(shù)據(jù)挖掘中的預(yù)處理
數(shù)據(jù)預(yù)處理是一種數(shù)據(jù)挖掘技術(shù),用于將原始數(shù)據(jù)轉(zhuǎn)換為有用且高效的格式。
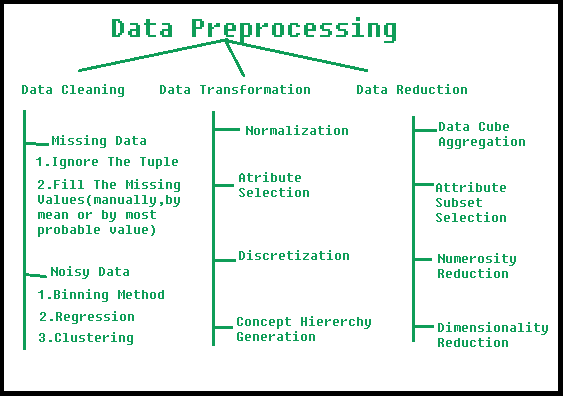 數(shù)據(jù)預(yù)處理涉及的步驟
數(shù)據(jù)預(yù)處理涉及的步驟
1. 數(shù)據(jù)清理:數(shù)據(jù)可能有許多不相關(guān)和缺失的部分。為了處理這部分,完成了數(shù)據(jù)清理。它涉及處理缺失數(shù)據(jù)、嘈雜數(shù)據(jù)等。
- 缺失數(shù)據(jù):當(dāng)數(shù)據(jù)中缺少某些數(shù)據(jù)時(shí),會(huì)出現(xiàn)這種情況。它可以通過(guò)多種方式處理。
- 他們之中有一些是:
- 忽略元組:僅當(dāng)我們擁有的數(shù)據(jù)集非常大并且元組中缺少多個(gè)值時(shí),此方法才適用。
- Fill the Missing values(填充缺失值):有多種方法可以完成此任務(wù)。您可以選擇按屬性平均值或最可能值手動(dòng)填充缺失值。
- 干擾數(shù)據(jù):干擾數(shù)據(jù)是機(jī)器無(wú)法解釋的無(wú)意義數(shù)據(jù)。它可能是由于數(shù)據(jù)收集錯(cuò)誤、數(shù)據(jù)輸入錯(cuò)誤等而生成的。可以通過(guò)以下方式處理它:
- Binning Method(分箱方法):此方法適用于已排序的數(shù)據(jù),以便使其平滑。將整個(gè)數(shù)據(jù)分成大小相等的段,然后執(zhí)行各種方法完成任務(wù)。每個(gè)分段都是單獨(dú)處理的。可以用其平均值或邊界值替換 segment 中的所有數(shù)據(jù),以完成任務(wù)。
- 回歸:這里可以通過(guò)將數(shù)據(jù)擬合到回歸函數(shù)來(lái)使數(shù)據(jù)變得平滑。使用的回歸可以是線性的(具有一個(gè)自變量)或多個(gè)的(具有多個(gè)自變量)。
- 聚類(lèi):此方法將集群中的相似數(shù)據(jù)分組。異常值可能未被檢測(cè)到,或者會(huì)落在集群之外。
2. 數(shù)據(jù)轉(zhuǎn)換:采取此步驟是為了將數(shù)據(jù)轉(zhuǎn)換為適合挖掘過(guò)程的適當(dāng)形式。這涉及以下方式:
- 規(guī)范化:這樣做是為了在指定范圍(-1.0 到 1.0 或 0.0 到 1.0)內(nèi)縮放數(shù)據(jù)值
- Attribute Selection:在此策略中,從給定的屬性集構(gòu)建新屬性以幫助挖掘過(guò)程。
- 離散化:這樣做是為了用區(qū)間級(jí)別或概念級(jí)別替換數(shù)字屬性的原始值。
- 概念層次結(jié)構(gòu)生成:此處,屬性在層次結(jié)構(gòu)中從較低級(jí)別轉(zhuǎn)換為較高級(jí)別。例如,屬性 “city” 可以轉(zhuǎn)換為 “country”。
3. 數(shù)據(jù)縮減:數(shù)據(jù)縮減是數(shù)據(jù)挖掘過(guò)程中的關(guān)鍵步驟,涉及在保留重要信息的同時(shí)減小數(shù)據(jù)集的大小。這樣做是為了提高數(shù)據(jù)分析的效率并避免模型過(guò)度擬合。數(shù)據(jù)縮減涉及的一些常見(jiàn)步驟包括:
- Feature Selection(特征選擇):這涉及從數(shù)據(jù)集中選擇相關(guān)特征的子集。執(zhí)行特征選擇通常是為了從數(shù)據(jù)集中刪除不相關(guān)或冗余的特征。可以使用各種技術(shù)來(lái)完成,例如相關(guān)性分析、互信息和主成分分析 (PCA)。
- 特征提取:這涉及將數(shù)據(jù)轉(zhuǎn)換為低維空間,同時(shí)保留重要信息。當(dāng)原始特征具有高維和復(fù)雜時(shí),通常會(huì)使用特征提取。可以使用 PCA、線性判別分析 (LDA) 和非負(fù)矩陣分解 (NMF) 等技術(shù)來(lái)完成。
- 采樣:這涉及從數(shù)據(jù)集中選擇數(shù)據(jù)點(diǎn)的子集。采樣通常用于減小數(shù)據(jù)集的大小,同時(shí)保留重要信息。可以使用隨機(jī)抽樣、分層抽樣和系統(tǒng)抽樣等技術(shù)來(lái)完成。
- 聚類(lèi):這涉及將相似的數(shù)據(jù)點(diǎn)分組到集群中。聚類(lèi)通常用于通過(guò)將相似的數(shù)據(jù)點(diǎn)替換為具有代表性的質(zhì)心來(lái)減小數(shù)據(jù)集的大小。可以使用 k-means、分層聚類(lèi)和基于密度的聚類(lèi)等技術(shù)來(lái)完成此操作。
- 壓縮:這涉及在保留重要信息的同時(shí)壓縮數(shù)據(jù)集。壓縮通常用于減小數(shù)據(jù)集的大小,以便進(jìn)行存儲(chǔ)和傳輸。可以使用小波壓縮、JPEG 壓縮和 gif 壓縮等技術(shù)來(lái)完成。
如何使用數(shù)據(jù)預(yù)處理?
我們之前已經(jīng)指出,這是數(shù)據(jù)預(yù)處理在機(jī)器學(xué)習(xí)和 AI 應(yīng)用程序開(kāi)發(fā)的早期階段很重要的原因之一。在 AI 環(huán)境中,應(yīng)用數(shù)據(jù)預(yù)處理是為了優(yōu)化用于清理、轉(zhuǎn)換和構(gòu)建數(shù)據(jù)的方法,從而以更少的計(jì)算能力提高新模型的準(zhǔn)確性。
一個(gè)出色的數(shù)據(jù)預(yù)處理步驟將有助于開(kāi)發(fā)一組組件或工具,這些組件或工具可用于快速構(gòu)建一組想法的原型,甚至可以運(yùn)行實(shí)驗(yàn)來(lái)改進(jìn)業(yè)務(wù)流程或客戶(hù)滿(mǎn)意度。例如,預(yù)處理可以通過(guò)增強(qiáng)用于分類(lèi)的客戶(hù)年齡范圍來(lái)增強(qiáng)推薦引擎的數(shù)據(jù)排列方式。
它還可以使開(kāi)發(fā)和增強(qiáng)數(shù)據(jù)的過(guò)程更容易,以獲得更增強(qiáng)的 BI,這對(duì)業(yè)務(wù)有益。例如,客戶(hù)的小規(guī)模、類(lèi)別或區(qū)域在不同區(qū)域可能具有不同的行為。將數(shù)據(jù)后端處理為正確的格式可能使 BI 團(tuán)隊(duì)能夠?qū)⒋祟?lèi)發(fā)現(xiàn)集成到 BI 控制面板中。
從廣義上講,數(shù)據(jù)預(yù)處理是 Web 挖掘的一個(gè)子過(guò)程,用于客戶(hù)關(guān)系管理 (CRM)。通常可以對(duì) Web 使用日志進(jìn)行預(yù)處理,以獲得有意義的數(shù)據(jù)集,這些數(shù)據(jù)集稱(chēng)為用戶(hù)事務(wù),實(shí)際上是一組 URL 引用。可以存儲(chǔ)會(huì)話(huà)以識(shí)別用戶(hù)身份以及請(qǐng)求的網(wǎng)站及其使用順序和時(shí)間。一旦從原始數(shù)據(jù)中提取出來(lái),這些就會(huì)提供更有意義的信息,可用于消費(fèi)者分析、產(chǎn)品促銷(xiāo)或定制等。
結(jié)論
數(shù)據(jù)預(yù)處理在數(shù)據(jù)質(zhì)量檢查和分析檢查中都起著核心作用。通過(guò)這種方式,數(shù)據(jù)挖掘過(guò)程變得有效,并且這些步驟得到的結(jié)果是準(zhǔn)確的。準(zhǔn)確地說(shuō),數(shù)據(jù)預(yù)處理過(guò)程中遵循的過(guò)程可能因數(shù)據(jù)集而異,或者取決于所需的分析。
有關(guān)數(shù)據(jù)挖掘中數(shù)據(jù)預(yù)處理的常見(jiàn)問(wèn)題解答 – 常見(jiàn)問(wèn)題解答
什么是數(shù)據(jù)預(yù)處理?
數(shù)據(jù)預(yù)處理提高了數(shù)據(jù)的質(zhì)量,從而使其適合分析。它最大限度地減少了錯(cuò)誤、變化和重復(fù),從而提高了獲得正確結(jié)果的可能性。
數(shù)據(jù)清洗過(guò)程中可以采用哪些方法?
其中一些是插補(bǔ)的缺失數(shù)據(jù)機(jī)制、可以刪除的復(fù)制實(shí)例的情況、分箱或回歸的干擾數(shù)據(jù),以及分組的類(lèi)似數(shù)據(jù)點(diǎn)。
數(shù)據(jù)轉(zhuǎn)換如何協(xié)助數(shù)據(jù)挖掘?
就數(shù)據(jù)分析而言,數(shù)據(jù)轉(zhuǎn)換涉及將數(shù)據(jù)轉(zhuǎn)換為更有用的形式的過(guò)程。規(guī)范化、離散化和概念層次結(jié)構(gòu)生成是用于對(duì)齊數(shù)據(jù)以增強(qiáng)挖掘的一些方法。





















工程師必備
- 項(xiàng)目客服
- 培訓(xùn)客服
- 平臺(tái)客服
TOP




