



訓練集和測試集的分布差距太大有好的處理方法嗎? 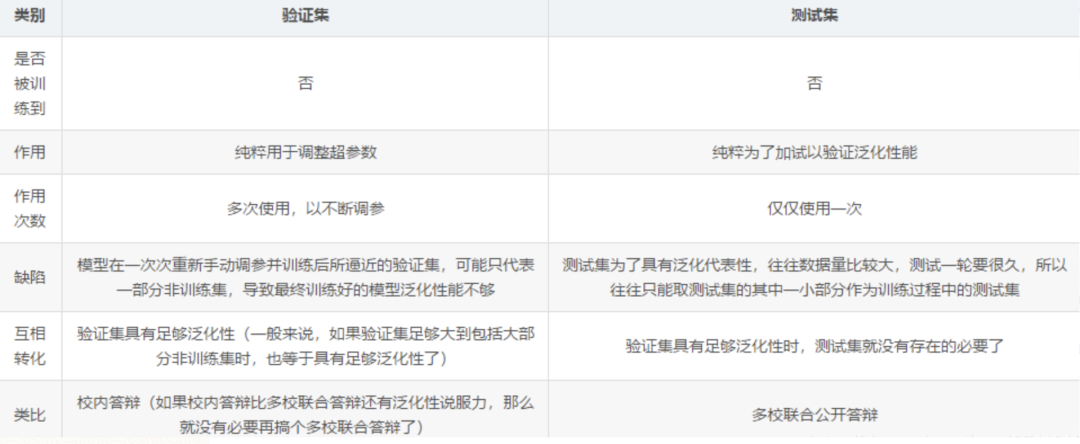
二是超參數很多時候不適合在訓練集上進行訓練,例如:如果在訓練集上訓練能控制模型容量的超參數,這些超參數總會被訓練成使得模型容量最大的參數(因為模型容量越大,訓練誤差越小),所以訓練集上訓練超參數的結果就是模型絕對過擬合。正因為超參數無法在訓練集上進行訓練,因此我們單獨設立了一個驗證集,用于選擇(人工訓練)最優的超參數。
3076
牛頓家的計算機 ??? 3年前
yolov7-pytorch可用于訓練自己的數據集 
trainval_percent用于指定(訓練集+驗證集)與測試集的比例,默認情況下 (訓練集+驗證集):測試集 = 9:1。train_percent用于指定(訓練集+驗證集)中訓練集與驗證集的比例,默認情況下 訓練集:驗證集 = 9:1。
2279
機器學習AI算法工程 ??? 3年前
74基于matlab的PSO-ELM的多輸入,單輸出結果預測,輸出訓練集和測試機預測結果及誤差 
基于matlab的PSO-ELM的多輸入,單輸出結果預測,輸出訓練集和測試機預測結果及誤差,適應度值。數據可更換自己的,程序已調通,可直接運行。
1761 6
matlab應用與學習 ??? 2年前
直播預告 | 基于VTD的Lidar訓練數據集構建方案分享 
VTD可以提供自動駕駛數據集所需的全部數據,通過腳本完成數據格式和數據形式的整理后,可以獲得對標真實數據的自動駕駛數據集。本期??怂箍抵辈ブv堂請到了自動駕駛仿真專家葉立斌老師為我們帶來基于VTD的Lidar數據集構建方案,從激光雷達物理建模到數據集獲取方案,為我們帶來高質量數據獲取的最新方法,敬請關注!
2250
??怂箍翟O計與仿真 ??? 1年前
用于圖像分類的頂級預訓練模型 
使用大型數據集和計算資源進行良好擴展。 應用:一般圖像分類和大規模視覺任務。 用于圖像分類的預訓練模型的優勢 減少訓練時間:預訓練模型顯著縮短了訓練時間。由于它們已經在大型數據集上進行了訓練,因此只需要針對特定任務進行微調。這種效率使開發人員能夠更快地部署模型。 提高準確性:這些模型已經在大量數據上進行了訓練,使它們能夠很好地泛化。
5398 30 10
仿真資料吧 ??? 1年前
SimData深度解析:高保真虛擬數據集的構建與評測 
1、基礎性能:虛擬數據具備可用性在SimData劃分的訓練集(30個場景)上訓練,并在測試集(15個場景)上評估,模型展現了良好的收斂性。 結果:mAP達到 0.446,NDS達到 0.428。 結論:SimData能夠支持復雜感知模型的正常訓練與推理,數據質量合格。
2269
康謀keymotek ??? 5月前
用Python控制Comsol自動運行方法(三):構建并訓練深度神經網絡代理模型 
5.讀取csv文件數據來構建并訓練DNN模型訓練后的DNN模型對E_vol和P_vol_ave的預測效果如下圖所示 訓練集(藍色點)和測試集(橘色點)基本都集中在理想預測線(紅色虛線:代表預測值等于實際值)附近,且R^2的值都在0.99以上,說明該模型具備比較優異的預測能力,可以作為一個合格的代理模型。
3981
鋰電芯動 ??? 11月前
成功案例丨開發時間從1小時縮短到3分鐘:如何利用歷史數據訓練AI模型,預測設計性能? 
</p><p><br></p><p>為了充分利用PhysicsAI,Hero首先將現有數據分為訓練集和測試集:訓練集用于基于歷史仿真數據訓練機器學習模型,測試集則用于評估和量化AI模型的預測準確性。由于Hero的產品線涵蓋多種車型(如運動型摩托車、探險摩托車、通勤摩托車和巡航車等),團隊使用了多樣化的把手數據集,以確保AI模型能夠生成準確的結果。
3341
ALTAIR ??? 1年前
SimData:基于aiSim的高保真虛擬數據集生成方案 
配合cv2或matplotlib可以對數據集進行可視化:具有gt框的六路攝像頭輸出: 同步lidar點云,可以同時繪制出bev視角下的標注信息2、bevformer檢測效果展示以下是使用在nuScenes數據集下訓練的權重,采用bevformer-tiny模型直接進行檢測的效果(即沒有在SimData上進行訓練)。
2375
康謀keymotek ??? 6月前
如何處理 TensorFlow 模型中的過擬合?
80% 的數據分配給訓練/驗證組合集,進一步分為 75% 用于訓練,25% 用于驗證,而 20% 分配給測試集以評估訓練模型的性能。
2414 1
仿真資料吧 ??? 1年前
在 Python 中使用 TensorFlow 進行面罩檢測 
示例數:2751 正面示例的百分比:50.163576881134134%,位置示例數:1380 負示例百分比:49.836423118865866%,負示例數:13715 步驟 3:拆分數據在此步驟中,我們將數據拆分為訓練集,該訓練集將包含將訓練 CNN 模型的圖像,以及包含將要測試模型的圖像的測試集。
2418 1
仿真資料吧 ??? 1年前
利用 Wolfram 語言構建的神經網絡促進學生的化學學習 
經過幾輪訓練后,兩個數據集都產生了準確度更高的訓練網絡: 下圖顯示了所有四個訓練網絡在四個數據集變體中的每一個的訓練時間和準確性。不出所料,與未增強的數據集相比,擴大的數據集需要更長的時間來訓練并提供更高的準確性。
2161
墨光科技 ??? 2年前
深度學習訓練營-使用 Python、Pytorch 的神經網絡
? 使用梯度下降算法訓練深度神經網絡 (DNN) 的基礎知識。? 將深度學習用于 IRIS 數據集。? 對 PyTorch 中的張量及其操作有深入的了解。? 構建和訓練從基本到復雜的神經網絡的能力。? 了解不同的損失函數、優化器和激活函數。? 一個完整的項目,關于從 MRI 圖像中檢測腦腫瘤,展示您在深度學習和 PyTorch 方面的技能。
3019 1
仿真資料吧 ??? 1年前
極限學習機matlab實戰 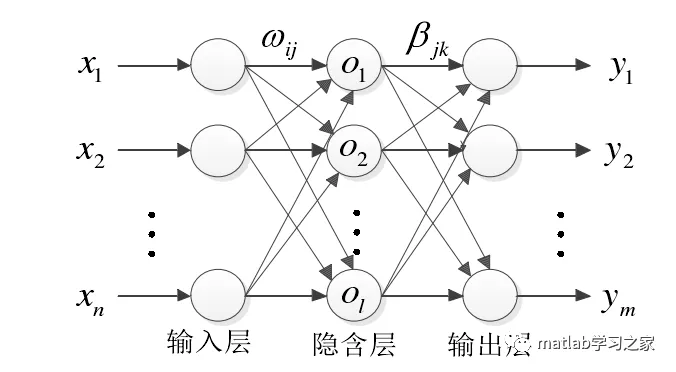
1、辛烷值的預測clear allclc%% 訓練集/測試集產生load spectra_data.mat% 隨機產生訓練集和測試集temp = randperm(size(NIR,1));% 訓練集——50個樣本P_train = NIR(temp(1:50),:)';T_train = octane(temp(1:50),:)
2221 2
Matlab心得交流 ??? 2年前
使用線性回歸預測降雨量 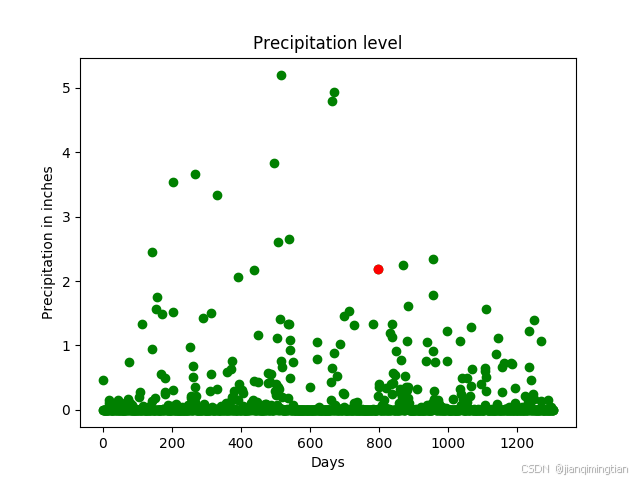
接下來,將數據分為兩組:訓練集和測試集。訓練集用于訓練模型,而測試集用于評估其性能。要執行線性回歸,我們首先需要定義一個假設函數,將輸入變量映射到輸出變量。
2447 3 1
仿真資料吧 ??? 1年前
【新聞】DTEmpower核心功能技術揭秘(5) - AIAgent模塊 
③ 實驗結果:通過表1和圖5不難發現,在船舶興波阻力數據集上,AIAgent訓練算法的R2、NRMSE、MAPE等指標均優于其他3種訓練算法,而在測試集上的擬合誤差圖也進一步說明了AIAgent訓練算法相較于普通訓練算法具有優越的泛化性能。
2130
天洑軟件 ??? 3年前
機器學習模型的集成方法總結:Bagging, Boosting, Stacking, Voting, Blending 
堆疊模型由多層組成,其中每一層由幾個機器學習模型組成,這些模型的預測用于訓練下一層模型。在疊加過程中,將數據分為訓練集和測試集兩部分。訓練集會被進一步劃分為k-fold?;A模型在k-1部分進行訓練,在k??部分進行預測。這個過程被反復迭代,直到每一折都被預測出來。然后將基本模型擬合到整個數據集,并計算性能。這個過程也適用于其他基本模型。來自訓練集的預測被用作構建第二層或元模型的特征。
2373 1
牛頓家的計算機 ??? 3年前
CFD專欄丨基于幾何深度學習的車輛空氣動力學快速預測 
Similarity Score=1表示待預測模型和訓練集中的其中一個模型剛好一樣;Similarity Score=0表示待預測模型和訓練集的最接近程度和訓練集內2個參考樣本的差異度一樣;Similarity Score<0表示待預測模型和訓練集的任何一個模型相似度很低。預測結果非常不可靠。
3105 1 1
ALTAIR ??? 7月前
設計仿真 | ODYSSEE機器學習方法助力提高傳動系統開發時效 
04基于仿真分析的輸入和輸出結果,構建機器學習訓練數據集和驗證數據集。05利用訓練集數據在ODYSSEE中進行機器學習快速預測模型搭建。06利用驗證集數據來對機器學習模型預測精度進行評估。
3129 1 1
海克斯康設計與仿真 ??? 10月前
XGBoost 工作原理詳解
近似貪心算法為高效處理大型數據集,XGBoost 采用近似方法尋找最優分裂:? 加權分位數:快速估算最優分裂點,無需遍歷所有可能? 效率優勢:在降低計算開銷的同時保持預測準確性? 適用場景:適用于全量評估成本過高的大型數據集XGBoost 的優勢? 可擴展性強:支持處理數百萬條記錄的大型數據集? 并行計算支持:支持并行處理和 GPU 加速,提升訓練效率
1983 1
仿真資料吧 ??? 4月前
20條/頁 
 16
16 跳至頁

技術鄰APP
工程師必備
工程師必備
- 項目客服
- 培訓客服
- 平臺客服
TOP
