



Abaqus批量提交計算的問題
如題:本人最近在嘗試編寫py腳本批量提交Job的計算,在個人電腦(i7-12700 32G DDR4平臺)上運行時能夠批量提交計算,但在服務器(26核×2個CPU 256G內存)上相同Abaqus相同版本運行同一段代碼(我修改了每一次提交計算的inp文件數,其它未變)卻會出現CPU占用很低,計算比個人電腦還慢的情況(見圖),請問這個問題要怎么解決?
2336 2
Jarvis_7267 ??? 2年前
ABAQUS批量提交Job與Python讀取ODB結果應力應變數據 
該網友的問題,實際上是兩個問題: 問題1是如何批量提交job; 問題2是如何從ODB結果文件中讀取計算結果數據。 因此本文也從兩個方面來進行介紹。 問題1 如何批量提交job——計算任務 批量提交計算任務這個問題實際上是老生常談了,可以用兩種基本的方式實現。
2728 4 1
CAEer吳皓 ??? 2年前
ABAQUS中inp文件批量提交計算程序 
ABAQUS批量提交inp自動計算bat程序
2487 5
北望逸塵 ??? 6年前
abaqus Python批量自動識別螺栓加載螺栓預緊力_完整代碼!.py 
abaqus Python批量自動識別螺栓加載螺栓預緊力,自動修改第二分析步為固定螺栓長度_完整代碼下載見付費內容! 因上傳不支持.py換成.txt格式上傳,下載后只需改一下后綴名為.py。按照下圖操作即可。
1924 2
dwg_2931 ??? 2年前
ABAQUS批處理修改inp、提交inp、提取odb--用于批量提取計算:如滯回曲線等 

(1)循環修改并生成inp文件 (2)批處理提交循環生成的inp文件 (3)批處理提取由批量提交計算的odb結果文件并生成excel本課程主要簡化ABAQUS界面繁瑣的操作,例如位移從1到10mm施加10次或者100次;速度從10到100m/s施加10次到100次等。批量處理采用python修改更加方便,可直接采用電腦計算,不用手動修改。
1541 33
了不起的大雄 ??? 4年前
abaqus運行py文件節點集錯誤?
abaqus不啟動GUI界面運行py文件顯示未知的節點集,在GUI界面下能運行成功,模型數據庫能查到節點名稱,這是哪的問題?
2424 4 1
? ? ? ??斯丹康 ??? 2年前
abaqus二次開發:前處理批量提交作業插件(源碼+注釋) 
abaqus二次開發:前處理批量提交作業插件(源碼+注釋) 購買后,請加V:wzd_1021_ 更多插件內容,請私聊 同時提供定制hypermesh/hyperview/abaqus前后處理插件開發。
1864
王振東 ??? 3年前
isight集成abaqus方法視頻(集成py文件,針對尺寸優化) 
通過一個實例(通過優化橫梁截面的尺寸,使得端部梁的變形最小)詳細介紹了isight集成abaqus方法,指出來了在集成中注意的問題(路徑設置、參數映射設置,批處理的編制,組件輸入輸出文件的配置,py文件的生成),這些在視頻中都有體現,該視頻為學習abaqus集成優化的學員提供了捷徑,視頻中未盡事宜可以后期提問解決,包解決你的難題
125 11
lz1234 ??? 8年前
abaqus中在inp文件批量導入節點力后,在荷載中沒有激活到下一步,此情況如何解決?
abaqus中在inp文件批量導入節點力后,在荷載中沒有激活到下一步,此情況如何解決?
2536 1
山珍海味熱切糕?? ??? 1年前
ABAQUS二次開發參數化建模
我想對abaqus進行二次開發,實現不打開abaqus就可以在自己創建 的一個GUI頁面里輸入模型參數等然后完成參數化建模。目前已完成下面功能:我目前寫了寫一個py,這個py文件的功能是可以進行參數化建模;然后還寫了一個py文件,它使用tkinter創建GUI并調用參數化建模的py文件,最后把這個創建GUI的代碼封裝為exe文件,封裝好的exe程序和參數化建模的Python文件放在同一文件夾下。
4002 1 2
小程序用戶_8ho4fOMu ??? 2年前
Abaqus中材料參數隨機場實現 
同樣的,批量生成inp使用其他語言一樣可以達成,如python。5、inp文件批量提交計算在abaqus中,有兩種方式提交模型計算,一種是從model的方式,另一種是從inp文件提交。
5656 28 11
文化人不大聰明 ??? 4年前
ABAQUS 批量讀取odb文件?
如何對N個odb文件,使用python批量讀取odb數據
2521 2 3
shady_2386 ??? 3年前
Abaqus提交作業不進入計算,log文件報錯如下,如何解決
\src\driverAnalysis.py", line 18, in _init File "SMAPylModules\SMAPylDriverPy.m|src\driverUtils.py", line 1824, in flattenMPIParamDictsdriverExceptions.MpiNoMpirun: {0
2782 1
用戶_43523 ??? 2年前
零基礎學習Abaqus Python二次開發(全套案例)
本課程將系統講解以下核心內容:Python基礎語法及與Abaqus的結合應用、Python數據結構/類/包的處理與應用、MDB和ODB根對象解析及相關命令、.rpy文件的理解與代碼修改、Python批量搭建模型、參數化建模插件開發、隨機參數建模代碼開發、作業自動提交腳本編寫、Python批量提取ODB相關數據、Python代碼細節優化避坑、可參考的實際開發案例。
2342 1
仿真資料吧 ??? 3月前
Abaqus python二次開發方法 附Abaqus Python Reader v1.9.4.1
python文件直接生成cae模型文件,可在py文件最后添加"mdb.saveAs(pathName='" *** "')"4) 可以通過cmd命令直接將py文件提交個abaqus內核,讓abaqus進行運算,cmd命令為“Shell "C:\Windows\SysWOW64\cmd.exe /k abaqus cae noGUI=" **** ".py ", vbHide等待abaqus
3748 12 6
知識通 ??? 4年前
Abaqus 熱-力順序耦合與 DFLUX 詳解
求解力學場提交 M-*.inp,Abaqus 將從 T-*.odb 讀取每一步對應的溫度場;檢查殘余應力分布(縱向/橫向/厚向)、等效塑性應變、焊后翹曲。后處理與掃參批量參數(幾何/工藝)→ 自動生成多組 T-*/M-*.inp → 批處理提交 → 統一提取峰值溫度、熔寬/熔深近似、最大殘余應力、變形等 → 建響應面或靈敏度分析。
3442 2
王詩兆 ??? 7月前
ABAQUS PYTHON二次開發攻略下載
python文件直接生成cae模型文件,可在py文件最后添加"mdb.saveAs(pathName='" *** "')"4) 可以通過cmd命令直接將py文件提交個abaqus內核,讓abaqus進行運算,cmd命令為“Shell "C:\Windows\SysWOW64\cmd.exe /k abaqus cae noGUI=" **** ".py ", vbHide等待abaqus
2731 1 1
分享菌 ??? 4年前
abaqus中材料參數隨機場的實現 
利用matlab生成隨機場數據,然后在abaqus中利用python將每個單元進行賦值,得到inp文件,最后利用python批量提交inp文件進行計算并提取計算結果,附件為所有用到的程序第一版和第二版程序的差別第一版程序的思路還是直接調用inp文件,利用inp文件中的節點和單元信息生成參數文件。然后在cae中對模型進行賦值。
18239 1 50
文化人不大聰明 ??? 3年前
ABAQUS 后處理的二次開發 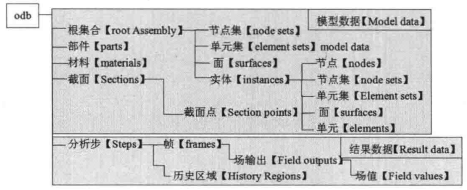
完成前處理操作后,新建名為ficldOperation的Job并提交運算,獲得fieldOperation.odb文件。 下面進行文件后處理的二次開發。 Step 1:在ABAQUS工作目錄下新建記事本文件,修改后綴名為.py。本例中Python文件命名為fieldOperation.py,代碼及說明如下。 Step 2:運行Python。
4113 4
CAEer吳皓 ??? 2年前
星辰技文|Abaqus中提取裂縫數據并用matplotlib庫繪圖 
單次或批量輸出圖片:可一次性輸出所有時刻、指定特定時刻、按時間間隔或按幀編號間隔批量輸出系列圖片; 2. 2D線圖輸出:由于繪制的是二維線圖,因此三維模型需要指定投影坐標系,目前支持XY、XZ、YZ、YX、ZX、ZY六種投影坐標系 3. 灰色背景線條:可指定單元Set集作為灰色背景線條,以指示天然裂縫、骨料邊界的位置; 4.
4835 20 5
星辰_北極星 ??? 2年前
20條/頁 
 16
16 跳至頁

技術鄰APP
工程師必備
工程師必備
- 項目客服
- 培訓客服
- 平臺客服
TOP
