



集成多組學數據的機器學習在生物醫學中的應用 
明確機器學習方法的適用性,優勢,以及局限性等 什么是機器學習機器學習的應用實例生物組學簡介(基因組學,轉錄組學,蛋白組學,代謝組學)機器學習在在多組學數據分析的應用 python基礎 目標:機器學習主流實現是python語言。
2251
。_4485 ??? 3年前
行業熱點丨AI 與機器學習:解讀AI術語,搶占數據時代發展先機 
</p><p><br></p><p>在機器學習中,數據會經過<strong>數據清理(去除不正確數據)、準備、可視化和建模</strong>等過程,以理解復雜的數據集。以下是一些機器學習類型的簡單介紹:</p><p><br></p><ul><li><strong>預測性分析:</strong>用數據預測接下來可能會發生的事。比如根據過去的天氣數據,預測明天會不會下雨。
2442
ALTAIR ??? 1年前
新聞速遞丨Altair連續兩年被 Gartner 魔力象限評為數據科學與機器學習平臺領導者 
我們認為,連續兩年被評為領導者,進一步證明了 Altair 在數據科學和機器學習領域的專業實力。我們提供完善的數據準備、AI 開發、流程編排與自動化解決方案,讓企業能夠更快速、更高效地將數據轉化為智能。我們始終致力于突破創新邊界,現在加入西門子后,我們將幫助客戶比以往更快速地構建、自動化和部署 AI。
2338
ALTAIR ??? 11月前
五分鐘學會python機器學習完成數據擬合1 

介紹了一個機器學習實現數據擬合的案例,希望對大家有所幫助。
56
活潑可男_matlab教學 ??? 1年前
機器學習 遷移學習 
數據集準備:Office-31、IRVI、GTA5、Cityscapes、Foggy cityscapes等注:硬件準備由主辦方提供云服務器九、實驗實操之深度遷移學習實踐1.掌握PyTorch中的基本原理和編程思想。2.理解在一個新的場景或數據集下,何時以及如何進行遷移學習。3.利用PyTorch加載數據、搭建模型、訓練網絡以及進行網絡微調操作。
2090
DSJ123 ??? 3年前
徑向基函數內核 – 機器學習 
Radial Basis Function Kernel - Machine Learning - GeeksforGeeks徑向基函數內核 – 機器學習內核在將數據轉換為更高維空間方面發揮著重要作用,使算法能夠學習復雜的模式和關系。在眾多的內核函數中,徑向基函數(RBF)內核作為一種多功能且強大的工具脫穎而出。
3613 23 8
仿真資料吧 ??? 1年前
自動機器學習綜述 
功能工程流程通常是這樣的:收集數據集,例如,從電子商務網站收集關于客戶行為的數據集。
2339
駕駛哥 ??? 4年前
設計仿真 | ODYSSEE機器學習方法助力提高傳動系統開發時效 
04基于仿真分析的輸入和輸出結果,構建機器學習訓練數據集和驗證數據集。05利用訓練集數據在ODYSSEE中進行機器學習快速預測模型搭建。06利用驗證集數據來對機器學習模型預測精度進行評估。
3131 1 1
海克斯康設計與仿真 ??? 10月前
機器學習模型的集成方法總結:Bagging, Boosting, Stacking, Voting, Blending 
來源:DeepHub IMBA作者:Abhay Parashar機器學習是人工智能的一個分支領域,致力于構建自動學習和自適應的系統,它利用統計模型來可視化、分析和預測數據。一個通用的機器學習模型包括一個數據集(用于訓練模型)和一個算法(從數據學習)。但是有些模型的準確性通常很低產生的結果也不太準確,克服這個問題的最簡單的解決方案之一是在機器學習模型上使用集成學習。
2373 1
牛頓家的計算機 ??? 3年前
基于深度學習的機器人目標識別和跟蹤 
但是我相信經過人們對于機器視覺領域的不斷研究,未來會有越來越多的基于深度學習的方法去優化目標跟蹤任務中出現的一系列情況,比如說采用大規模視頻數據的數據集進行離線訓練等等,在目標識別領域未來也將會降低環境對檢測的影響能更加精準的檢測各種大小的目標,并且最終將兩種技術更好的結合在一起應用到機器人技術應用的各個方面。
2278
DSJ123 ??? 3年前
基于機器學習的智能垃圾短信檢測超強系統 
核心功能模塊數據加載與預處理本文項目使用的是飛漿平臺提供的公開數據集,數據集中包含70萬條數據,該數據數據集已經被分詞處理好,采用的是jieba分詞工具。
2356
320科技工作室 ??? 6月前
OptiSystem應用:通過機器學習預測系統性能 
圖3.機器學習工具主參數選項卡選擇光纖長度、最小BER和Q因子作為需要預測的數據:a)選擇光纖長度作為需要預測數據b)選擇最小BER和Q因子作為需要預測數據圖4.在機器學習工具中選擇需要預測數據接著我們需要將1000次眼圖結果提取成圖片放入訓練集文件夾中,然后運行機器學習工具訓練神經網絡。如圖5,我們可以評價神經網絡的性能,查看損失函數。
2165
追光ing ??? 8月前
利用 Wolfram 語言構建的神經網絡促進學生的化學學習 
然而,我很快對缺乏面向化學的圖像數據集這一事實感到震驚,并在使用了修改后的國家標準與技術研究所 ( MNIST ) 手寫數據集示例后,決定創建這種類型的數據集。目標是為學生提供端到端的數據科學項目體驗,從創建數據到執行高級機器學習練習的最后一步。
2161
墨光科技 ??? 2年前
OptiSystem應用:通過機器學習預測系統性能 
圖3.機器學習工具主參數選項卡 選擇光纖長度、最小BER和Q因子作為需要預測的數據: a)選擇光纖長度作為需要預測數據 b)選擇最小BER和Q因子作為需要預測數據 圖4.在機器學習工具中選擇需要預測數據 接著我們需要將1000次眼圖結果提取成圖片放入訓練集文件夾中,然后運行機器學習工具訓練神經網絡
1532
信光嗎 ??? 8月前
基于大數據模型的數字孿生建模方法 
圖3 深度學習算法的分類 ③遷移學習:指一種學習或學習的經驗對另一種學習的影響,以深度卷積神經網絡為基礎,通過修改一個已經經過完整訓練的深度卷積神經網絡模型的最后幾層連接層,再使用針對特定問題而建立的小數據集進行訓練,以使其能夠適用于一個新問題。其放寬了傳統機器學習中的兩個基本假設,目的是遷移已有的知識來解決目標領域中僅有少量甚至沒有有標簽樣本數據的學習問題。
2354 2 1
機械設計師 ??? 4年前
17個機器學習的常用算法
根據數據類型的不同,對一個問題的建模有不同的方式。在機器學習或者人工智能領域,人們首先會考慮算法的學習方式。在機器學習領域,有幾種主要的學習方式。將算法按照學習方式分類是一個不錯的想法,這樣可以讓人們在建模和算法選擇的時候考慮能根據輸入數據來選擇最合適的算法來獲得最好的結果。1.
2385 1
王者歸來123 ??? 3年前
AI機器學習如何改變3D打印領域? 
●故障緩解使用機器學習進行自動故障檢測的研究已經在進行中,許多研究者在這個領域發表了文章。分析了打印過程的所有視頻,可以找到常見的故障模式,包括導致錯誤的特定高度、形狀、運動和模型。進一步訪問用戶設置會生成一個非常大的有關打印失敗的數據集,可以用來避免常見錯誤或找出正確的設置。●過程監控過程監控可以盡早發現錯誤,許多3D打印公司也在追求這一點。
2009 2
南極熊3D打印 ??? 3年前
“深度學習一點也不難!”
為什么遷移學習是下一代機器學習軟件的關鍵?本文開頭我提到了使用機器學習(尤其是深度學習)需要具備的有利條件。你需要一個大型的數據集,需要設計有效的模型,而且還需要訓練的方法。這意味著一般而言,某些領域的項目或缺乏某些資源的項目就無法開展。如今,我們可以利用遷移學習消除這些瓶頸:1、小型數據集不再是問題通常,深度學習需要大量帶標簽的數據,但在許多領域中,這些數據根本不存在。
2104 3 2
龍騰AI技術 ??? 3年前
訓練集和測試集的分布差距太大有好的處理方法嗎? 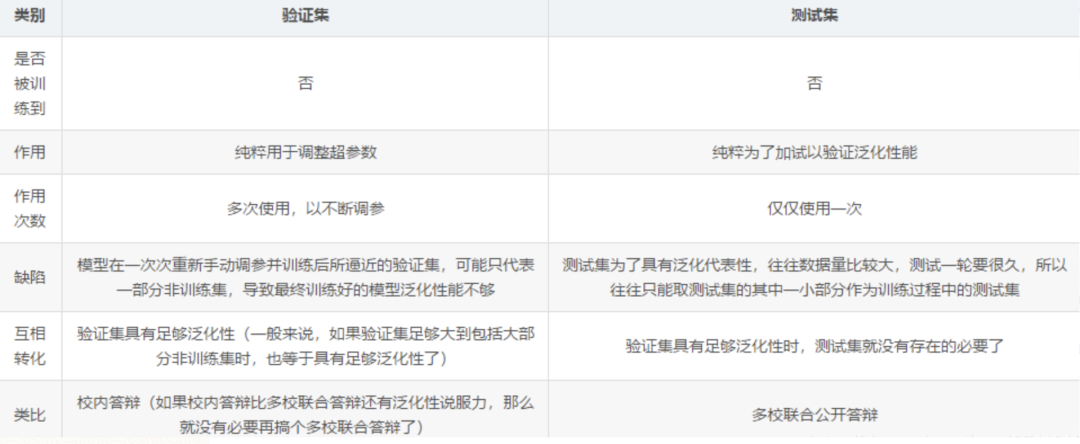
機器學習常見步驟1.對數據集進行劃分,分為訓練集和測試集兩部分;2.對模型在測試集上面的泛化性能進行度量;3.基于測試集上面的泛化性能,依據假設檢驗來推廣到全部數據集上面的泛化性能。三種數據集的含義在進行機器學習算法之前,通常需要將數據集劃分,通常分為訓練集和測試集,部分還有驗證集。
3077
牛頓家的計算機 ??? 3年前
直播預告-基于機器學習的車輛行人保護頭部仿真研究 
SFE 參數化模型與傳統CAE 模型加速度精度對標機器學習模型訓練和驗證SFE參數化模型搭建的頭碰模型精度達標后,可以使用其對DOE分出的120組模型分別計算,作為機器學習訓練樣本。選擇其中110組作為訓練集樣本點,5組作為驗證集樣本點,剩余5組為預測集樣本點。使用ODYSSEE 軟件,可以在一分鐘的時間內完成上述76組、每組110條曲線的訓練。
2243
海克斯康設計與仿真 ??? 2年前
20條/頁 
 54
54 跳至頁

技術鄰APP
工程師必備
工程師必備
- 項目客服
- 培訓客服
- 平臺客服
TOP
