



ZEMAX軟件技術(shù)應(yīng)用專題:關(guān)于Opticstudio選用核數(shù)跟優(yōu)化速度的關(guān)系 
如果一臺計(jì)算機(jī)使用多個CPU進(jìn)行計(jì)算,系統(tǒng)并不總是需要使用所有的CUPs。下面的圖片顯示了一個多CPU/線程工作方式的例子。 有些計(jì)算只由一個CPU/線程(母線程)執(zhí)行。 在這段時間里,CPU的利用率很低。有些部分需要多個CPU/線程(平行區(qū)域)。 在這段時間里,CPU的利用率很高。如果在OpticStudio中為計(jì)算配置了N-cores,OpticStudio
2503
w**elab86_Swsp ??? 3年前
解密一顆芯片設(shè)計(jì)的全生命周期算力需求 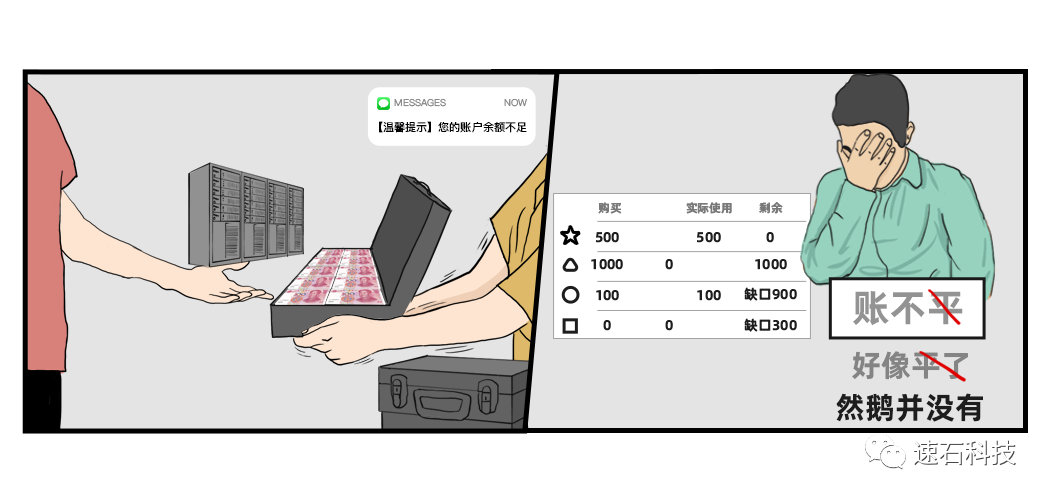
Step 1:將不同組、每個job所需核數(shù)或內(nèi)存的峰值需求,依次填入中間的“每job峰值核數(shù)”和“每job峰值內(nèi)存”欄目下,負(fù)責(zé)人填入“團(tuán)隊(duì)負(fù)責(zé)人”欄目下例如:每個job需要的峰值核數(shù)為10,每個job需要峰值內(nèi)存為20(據(jù)經(jīng)驗(yàn)值統(tǒng)計(jì)),前端負(fù)責(zé)人為Andy。
2081
白話ic ??? 3年前
Mechanical 分布式計(jì)算與共享內(nèi)存的測試
硬件16核32線程,64G內(nèi)存,無顯卡加速工況1: Distributed 16 cores工況2: Non Distributed,32 cores計(jì)算用時比較: 工況1 工況2用時 1h46m 5h49m內(nèi)存 12.6G 8.9G結(jié)論: 用分布式(在solve中勾選Distributed復(fù)選框)計(jì)算,只能使用物理核數(shù)
2711
仿真工匠 ??? 4年前
CAE/CFD云仿真免費(fèi)試用│ LS-DYNA求解效率深度測評,六種規(guī)模,本地VS云端5種不同硬件配 
實(shí)證場景一:不同類型配置本地 VS 云端計(jì)算優(yōu)化型實(shí)例 VS 云端通用型實(shí)例 VS 云端內(nèi)存優(yōu)化型實(shí)例 結(jié)論:1、同等核數(shù)下,云端計(jì)算優(yōu)化型實(shí)例的表現(xiàn)優(yōu)于通用型實(shí)例、內(nèi)存優(yōu)化型實(shí)例和本地計(jì)算資源;2、隨著核數(shù)的上升,由于節(jié)點(diǎn)間通信開銷指數(shù)級上升,性能的提升隨著線程數(shù)增長逐漸變緩。
3132 6 3
技術(shù)鄰公告 ??? 3年前
【Abaqus電腦配置】CPU選Intel還是AMD? 
RAM內(nèi)存條要結(jié)合CPU內(nèi)存通道和總帶寬進(jìn)行匹配,選頻率高的,在預(yù)算范圍內(nèi)把內(nèi)存通道插滿,不要閑置。內(nèi)存容量應(yīng)根據(jù)CPU核數(shù)與求解器類型來定,推薦的核數(shù)與內(nèi)存容量配比為,Explicit求解器1:4,Standard求解器1:8,比如CPU已定8核,機(jī)器主要運(yùn)行Abaqus/Explicit,那么RAM可以定為32G,4通道的話就買4條8G的內(nèi)存條插滿即可。
9187 70 41
USim ??? 4年前
LS-DYNA數(shù)值計(jì)算并行內(nèi)存分配?
LS-DYNA并行求解的時候是不是核數(shù)越多計(jì)算的越快啊?該怎么設(shè)置?有的時候用AMD的cpu求解的時候總是報分配內(nèi)存錯誤是什么原因啊?有沒有大佬遇到過,求指導(dǎo)!!!?
2297 3
。!?“@” ??? 1年前
技術(shù)分享︱大型稀疏線性方程組求解技術(shù)——工業(yè)仿真的底層核心 
在共享內(nèi)存環(huán)境中,稀疏線性方程組求解算法的可擴(kuò)展性問題也需要特別關(guān)注。因?yàn)楝F(xiàn)代多核/眾核處理器上的核數(shù)在可預(yù)見的未來也將越多,在單個CPU上封裝數(shù)十甚至上百個有較強(qiáng)處理能力的核心,或是在GPU上封裝成千上萬個輕量級處理單元將變得非常普遍。如何在這種共享內(nèi)存節(jié)點(diǎn)上實(shí)現(xiàn)細(xì)粒度的并行仍然是很有挑戰(zhàn)的研究內(nèi)容。
2482
神工坊(高性能仿真) ??? 9月前
第一款96核4.8GHz--超頻工作站GR450P上市 
硬件特點(diǎn):§ 采用AMD 銳龍TR PRO 7900WX/銳龍TR 7900X處理器,單CPU最大核數(shù)96個,三級緩存L3高達(dá)384MB,支持8個內(nèi)存通道,其高主頻、大緩存、大內(nèi)存帶寬特點(diǎn),是目前單CPU多核并行算力的最強(qiáng)科學(xué)計(jì)算處理器。
2425 1 1
UltraLAB ??? 2年前
2023年MATLAB科學(xué)計(jì)算工作站及集群配置方案 
,頻率最高到4.3GHz,核數(shù)最大112,內(nèi)存6TB,24通道,優(yōu)勢:擁有高頻+最大內(nèi)存帶寬,適合CAE仿真計(jì)算、量子化學(xué)、分子動力模擬計(jì)算等。
2924
UltraLAB ??? 2年前
FEKO中內(nèi)存消耗的預(yù)估方法 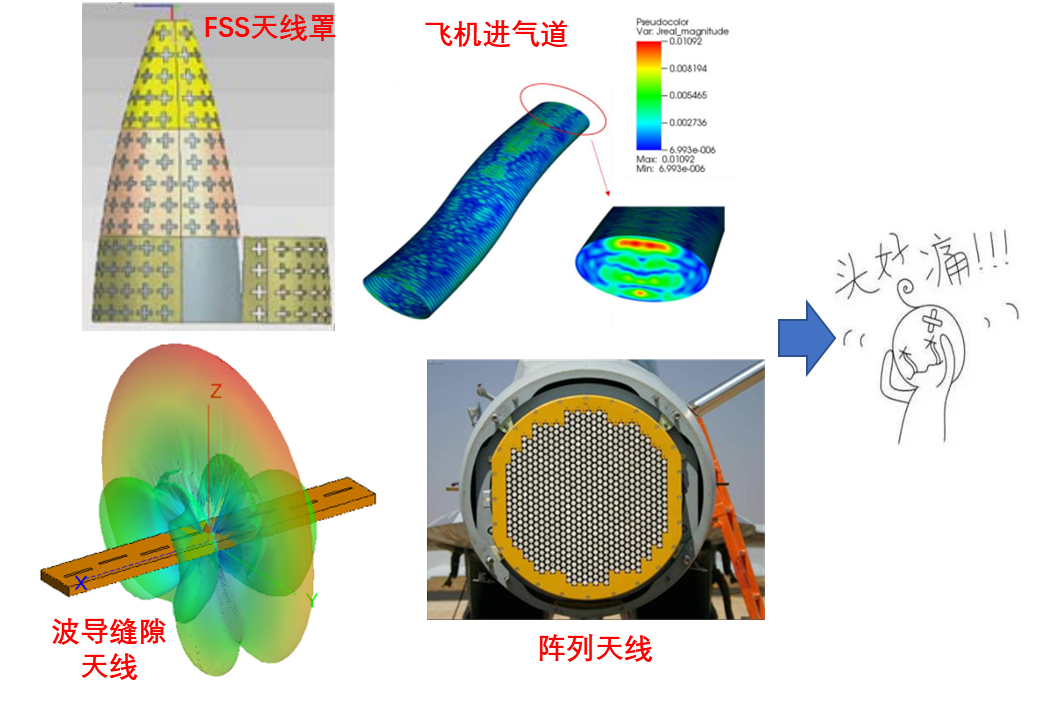
如果你經(jīng)常使用FEKO進(jìn)行仿真計(jì)算,對于結(jié)構(gòu)相對簡單,不含有復(fù)雜精細(xì)結(jié)構(gòu)的電磁模型的網(wǎng)格與內(nèi)存消耗之間的對應(yīng)關(guān)系,應(yīng)該有著大致的概念。
2904
萬有引力LYQ ??? 2年前
新品上市-圖靈超頻工作站GT430M介紹 
整個機(jī)器在高頻狀態(tài)下,單核計(jì)算與多核并行計(jì)算、GPU超算、高速讀寫保證軟件各個環(huán)節(jié)完美運(yùn)行,可大幅縮短計(jì)算或處理時間,多核性能媲美雙Xeon可擴(kuò)展處理器架構(gòu)硬件特點(diǎn): 采用Intel Xeon W-3400超頻處理器,單CPU最大核數(shù)56核@4.2GHz,三級緩存L3高達(dá)105MB,支持8個內(nèi)存通道,其高主頻、大緩存、大內(nèi)存帶寬特點(diǎn),是目前單CPU多核并行算力的最強(qiáng)科學(xué)計(jì)算處理器。
2039
UltraLAB ??? 3年前
一變?nèi)鼳nsys仿真計(jì)算加速神器--UltraLAB PCA介紹 
圖1如何更有效的利用超級圖形工作站的四顆Xeon的多核和完美的內(nèi)存帶寬,發(fā)揮最高的計(jì)算效能,西安坤隆計(jì)算機(jī)公司專注高性能計(jì)算應(yīng)用,為此開發(fā)的PCA(Parallel Computing Acclerator,并行計(jì)算加速器),工作站預(yù)裝PCA,大幅提升機(jī)器多核并行計(jì)算使用率,翻倍提升計(jì)算速度。
2510
UltraLAB ??? 3年前
Abaqus & AMD,兼容和并行效率的那些事~ 
下面是計(jì)算時間結(jié)果對比,采用相同的核數(shù),一面是單個節(jié)點(diǎn)運(yùn)行,一面是將作業(yè)平均分配到4個節(jié)點(diǎn)上。在核數(shù)相同的情況下,采用混合并行模式將大大降低計(jì)算時間。
3623
神工坊(高性能仿真) ??? 3年前
Abaqus并行效率二三事 
下面是計(jì)算時間結(jié)果對比,采用相同的核數(shù),一面是單個節(jié)點(diǎn)運(yùn)行,一面是將作業(yè)平均分配到4個節(jié)點(diǎn)上。在核數(shù)相同的情況下,采用混合并行模式將大大降低計(jì)算時間。
4610 5 2
big膽! ??? 3年前
Materials Studio材料建模與模擬計(jì)算工作站方案2021v4 
,密度泛函(DFT): 內(nèi)存容量大,大量I/O臨時文件第二類:平面波贗勢密度泛函: CPU算力、內(nèi)存容量、內(nèi)存帶寬如果追求最快算力,只有四路Xeon架構(gòu)最合適(高主頻+并行核數(shù)+24通道)2.4 分子力學(xué)與分子動力學(xué)類算法計(jì)算特點(diǎn)經(jīng)典分子動力學(xué)模擬中,計(jì)算成本取決于原子數(shù)N,分子動力學(xué)不會占用太多內(nèi)存,以CPU算力為主,由于輸出大量軌跡數(shù)據(jù),需要大容量硬盤,硬件配置特點(diǎn):CPU 算力越大越好
4106
UltraLAB ??? 4年前
SolidWorks打開多個文件報內(nèi)存錯處理方法 
正常情況,以上處理完畢后,基本接沒有問題了,但是如果還是不行,就說明跟solidworks沒有多大關(guān)系了,可能是其他軟件引起的沖突,
下面的內(nèi)容不建議購買,只是提供一個問題的解決思路!!不一定能夠解決問題!!!!
下面的內(nèi)容不建議購買,只是提供一個問題的解決思路!!不一定能夠解決問題!!!!
下面的內(nèi)容不建議購買,只是提供一個問題的解決思路!!
3455 1 1
王毅 ??? 3年前
UltraLAB油藏數(shù)值模擬工作站 
No環(huán)節(jié)主要模塊求解加速手段計(jì)算特點(diǎn)1預(yù)處理Builder前處理模塊DynaGraid動態(tài)網(wǎng)格雅閣比陣列構(gòu)建單核計(jì)算,CPU睿頻越高,網(wǎng)格生成越快2求解? IMEX黑油模擬器? GEM組分模擬器? STARS熱采及化學(xué)驅(qū)模擬器Parasol并行求解器多核并行計(jì)算核數(shù)無限制CMOST AI多層神經(jīng)網(wǎng)絡(luò)驅(qū)動貝葉斯引擎多核CPU并行計(jì)算高內(nèi)存帶寬,CPU高頻AUTOTUNE AI人工智能模型、參數(shù)優(yōu)化多核
2377
Aries333 ??? 2年前
結(jié)構(gòu)/流體/多物理場/電磁仿真最快最完美工作站集群22v4 
要點(diǎn)3 基于有限元分析法(結(jié)構(gòu)仿真、流體仿真)的最快計(jì)算架構(gòu):CPU超高頻+有限多核+高內(nèi)存帶寬,Alpha750機(jī)型是目前最快的仿真計(jì)算工作站。要點(diǎn)4 支持雙子星架構(gòu)(2臺工作站通過Infiniband高速直連),最高核數(shù)達(dá)到224個,具有微型仿真集群的算力,計(jì)算效率更高,易于維護(hù)。
2114
UltraLAB ??? 3年前
在“神工坊”上使用OpenRadioss進(jìn)行大規(guī)模并行仿真,效果如何? 
需要注意的是,在使用“starter”模塊進(jìn)行前處理時所使用的CPU核數(shù),需要與后續(xù)使用“engine”模塊求解時所使用的核數(shù)保持一致。 “paraview”模塊為后處理模塊 。
2520
神工坊(高性能仿真) ??? 3年前
干貨|一文帶你搞懂內(nèi)存中數(shù)據(jù)的讀寫方式 
摘要 : 你知道內(nèi)存是怎么讀取數(shù)據(jù)的嗎? 知道數(shù)據(jù)是怎么一個一個字節(jié)發(fā)送的嗎? 是低字節(jié)先發(fā)還是高字節(jié)先發(fā)? 是bit0先發(fā)還是bit7先發(fā)? 是從低地址開始讀還是從高地址開始讀? 看完本篇你應(yīng)該就明白了~ 內(nèi)存的讀寫永遠(yuǎn)從低地址開始讀/寫,從低到高!從低到高!從低到高!
2568
電子工程世界EEWorld ??? 4年前
20條/頁 
 16
16 跳至頁

技術(shù)鄰APP
工程師必備
工程師必備
- 項(xiàng)目客服
- 培訓(xùn)客服
- 平臺客服
TOP
