



什么是雙活數據中心 ?雙活數據中心有哪些優點? 
有了云計算技術,不代表投入會更少,但是資源利用率會更高,系統但抗沖擊能力會更強,自由調度能力會更強。 自動化是“雙活”與“云計算”必不可少的前提條件 云計算需要自動化手段來幫助系統維護人員進行自動的資源調配。比如,通過虛擬化技術虛擬出了上萬臺虛擬機器,白天需要50臺機器給網銀系統提供web服務,晚上網銀交易少了,貴金屬交易多了,這50臺機器要調配到另一個系統上。
2548
智能化弱電工程設計與施工 ??? 4年前
經緯恒潤車隊數據采集解決方案 
但隨著數據采集的需求越來越多,在隨車人員的減少、工程師遠程分析、車隊遠程管理、輕便性和方便性等諸多方面存在需求。 而在實際使用中,大量使用工控機采集、老式的總線類工具、必需的隨車工程師等方式很難適應如今大數據量、高里程的要求。應用方面存在著邊界多、工程師人少、數據少、司機不專業、接口多且變化快、傳輸難、設備體積大等各類問題。
2128
經緯恒潤 ??? 4年前
設計仿真 | 家電行業仿真數據管理平臺方案 
03缺少仿真規范和系統支撐家電行業由于自身特點,當前仍有不少仿真分析沒有建立標準化分析清單和指標檢查規范,主要基于試驗或產品問題的被動分析;同時試驗或產品問題與仿真分析缺少數據追溯,不能有效實現問題清單閉環管理,缺少信息化系統的支撐;另外,常規重復性的工作耗時耗力、效率低,確少自動化支持。
3562 31 11
海克斯康設計與仿真 ??? 1年前
工業大數據正在改變制造業 
盡管自工業革命以來,經濟區域的技術飛躍相對較少,但制造業正受到大數據的影響。在未來的幾年里,如果想要繼續生產,更多的制造商將被鼓勵或被迫采用數據采集,存儲和分析的新標準。■未經授權,請勿轉載!
2163 3 4
型創科技2023 ??? 3年前
數據挖掘中的數據預處理 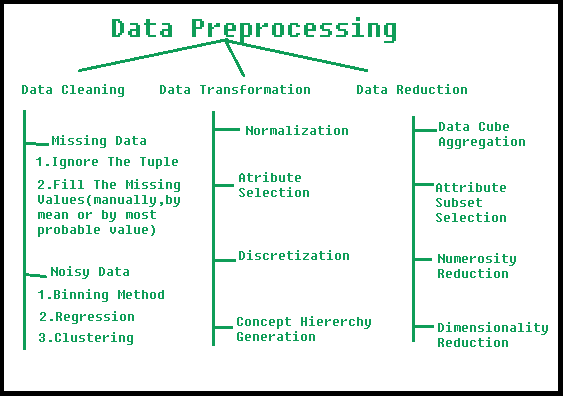
我們之前已經指出,這是數據預處理在機器學習和 AI 應用程序開發的早期階段很重要的原因之一。在 AI 環境中,應用數據預處理是為了優化用于清理、轉換和構建數據的方法,從而以更少的計算能力提高新模型的準確性。一個出色的數據預處理步驟將有助于開發一組組件或工具,這些組件或工具可用于快速構建一組想法的原型,甚至可以運行實驗來改進業務流程或客戶滿意度。
2547
仿真資料吧 ??? 1年前
數據分析和AI丨應對AI實施挑戰,工程領域AI應用的五大方法 
<strong>只收集和保護真正需要的信息,剔除那些低價值的數據</strong>,因為這些數據只會增加找到關鍵信息的難度。從小規模的數據開始,逐步優化和擴展。</p><p><br></p><p>工程領域中很多最具影響力的 AI 案例都利用了以往物理測試的歷史數據,這里歷史數據也是工程師多年來一直在產品開發中使用和信任的數據。但原始數據很少是完整、干凈和準確的。
2521
ALTAIR ??? 1年前
試驗臺底座:從“穩如老狗”到數據準,它默默扛下了所有 
試驗臺底座:從“穩如老狗”到數據準,它默默扛下了所有 在工業測試的一線,有個“功臣”,不張揚、不搶鏡,卻默默扛下了所有——它就是試驗臺底座。搞工業測試的同行都懂,一句“穩如老狗”,是對試驗臺底座的高評價。但很少有人知道,它的價值遠不止“穩”,從穩穩承載設備,到準支撐每一組測試數據,每一份靠譜的檢測結果背后,都是試驗臺底座在默默發力、默默擔當。
840
河北威岳 ??? 2月前
設計仿真 | AM STUDIO 增材制造數據準備解決方案 
wx_fmt=png&from=appmsg"></p><p class="ql-align-center"><strong>無支撐與少支撐技術</strong></p><p>打印效率也是定向需要考慮的因素之一,對于一個長方體,不管橫豎擺放,由于體積不變,激光實際掃描的時間都一樣,不同之處在于因層數導致的鋪粉時間差異,從而導致兩個定向方案的加工效率不同,一般情況下,層數越少,打印越快。
2595 1
海克斯康設計與仿真 ??? 1年前
FRED應用:數字化極坐標數據取樣 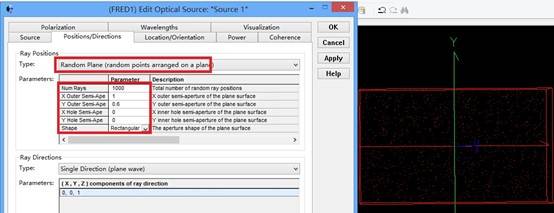
規格表為光源提供了強度數據,因此使用光線方向說明“Randomly according to intensity distribution”才是有意義的。該光線方向說明將會在球形極坐標網格上獲取強度分布,并且根據該分布輪廓統計隨機的光線方向(比如:強度最高的地方產生更多的光線,強度低的方向光線較少)。
1049
信光嗎 ??? 1月前
數字化極坐標數據取樣 
規格表為光源提供了強度數據,因此使用光線方向說明“Randomly according to intensity distribution”才是有意義的。該光線方向說明將會在球形極坐標網格上獲取強度分布,并且根據該分布輪廓統計隨機的光線方向(比如:強度最高的地方產生更多的光線,強度低的方向光線較少)。
2269 3
追光ing ??? 3年前
ENGEL sim link數據接口實現模流分析和射出機之間的直接數據傳輸 
這表明,機器不介入的情況下,通過模擬仿真,即使是復雜系統也可以快速地優化,而且模擬的迭代次數很少。 通過模擬不斷優化工藝我們使用sim link對上述模擬中的所有的初始設置進行確定,并進行修改,以適應選定的射出機——ENGEL duo 12060/1700。為了能夠在生產機器的基礎上進一步優化工藝,我們根據機器進行了工藝設置的修改,并再次進行了模擬。
2461
ACMT協會 ??? 1年前
全站儀數據采集和傳輸中的常見問題解決方案
坐標位數:小數點前少于或等于5位,小數點后3位 四、全站儀文件設置 1、最好只用英文字母或數字設置文件名2、點號:測站點坐標:可用“字母”+“數字” 碎部坐標:只用阿拉伯數字,從1開始,位數越少越好,以便展點畫圖。 五、定向方法 1、放樣模式下定向:最好用這種方式定向比較準。
4469
繪夢流光 ??? 3年前
康謀分享 | 確保AD/ADAS系統的安全:避免數據泛濫的關鍵! 
<strong>內容越少,處理和分析越快</strong>。此外,專注于更小的有效信息集合可以降低存儲成本和維護負擔。</p><p>為了減少初始內容池,可以創建<strong>有用的信息塊,</strong>或者說<strong>"指標(metrics)"</strong>,以更簡短和有意義的方式總結和描述它。
2322
康謀keymotek ??? 1年前
如何用數據分析找到更優的橡膠配方? 
數據驅動的多目標優化,不僅適用于橡膠配方,也能推廣到電池、醫藥、材料工藝設計等領域。它能讓研發人員少走彎路,更快做出既好用又經濟的材料方案。操作演示:全球100個AI應用案例電子書下載△Altair 正式發布全球100個AI應用案例電子書,內容覆蓋10+行業的100個AI應用場景。
2024 1 2
技術鄰公告 ??? 8月前
Ansys Zemax | 如何使用極探測器和 IESNA / EULUMDAT 光源數據 
極坐標圖顯示超過100°時入射能量很少。將圖進行 log-5 顯示:在180°范圍內有少量的能量。捕獲發射到 4*pi 球面度的光線的能力使極探測器能夠對任何光源特性進行顯示。現在極探測器中含有關于封裝的 LED 的信息,可以將這些數據導出為 IES 或 LDT 文件。
2422
宇熠科技 ??? 8月前
FRED應用:數字化極坐標數據取樣 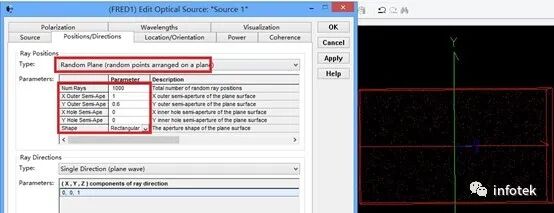
規格表為光源提供了強度數據,因此使用光線方向說明“Randomly according to intensity distribution”才是有意義的。該光線方向說明將會在球形極坐標網格上獲取強度分布,并且根據該分布輪廓統計隨機的光線方向(比如:強度最高的地方產生更多的光線,強度低的方向光線較少)。
2099
追光ing ??? 11月前
基于大數據模型的數字孿生建模方法 
它對于傳統的淺層學習器(如支持向量機、邏輯回歸等)而言是不可或缺的技術,因為數據和特征決定了機器學習的上限,而模型和算法只是逼近這個上限而已。對于深層學習器(如卷積神經網絡),由于存在特征自學習的隱藏層,可以自動學習原始數據中的敏感特征,對特征工程依賴較少。但是,隱藏層的特征自學習在深層學習的應用范圍是有限的,特征工程在深度學習依然有著不可替代的作用。
2354 2 1
機械設計師 ??? 4年前
技術 \\ 數據中心液冷化改造適用技術探析 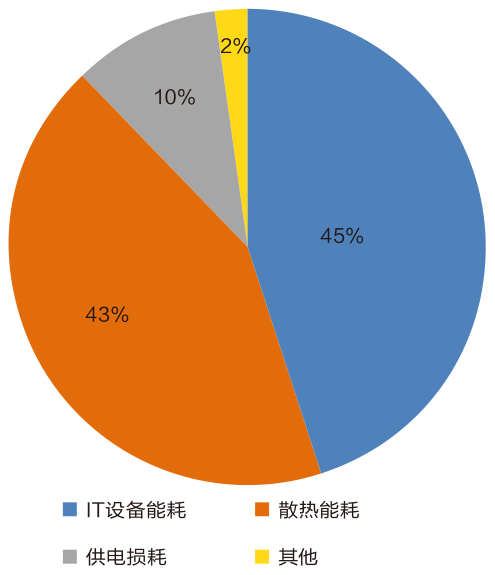
從市場占有情況分析,目前冷板式液冷數據中心產品市場上占比較高,互聯網巨頭以及數據中心設備企業多推出了商用化冷板式液冷服務器,但商用化的浸沒式液冷服務器很少,阿里巴巴等領先企業多采用企業定制化的浸沒式液冷服務器。
2376
解開動力 ??? 3年前
數據分析與AI丨如何用數據分析找到更優的橡膠配方?
數據驅動的多目標優化,不僅適用于橡膠配方,也能推廣到電池、醫藥、材料工藝設計等領域。它能讓研發人員少走彎路,更快做出既好用又經濟的材料方案。
2334
ALTAIR ??? 8月前
作為初學者你真的懂S7-200 SMART數據組合嗎? 
連接上PLC,把數據寫入對應的地址,然后監控需要求的地址數據。總結對于初學者來說,不會進制轉換可以使用計算器直接轉換。數據組合非常檢驗初學者的一個水平,這個組合在使用過程中用的比較少,主要要考慮使用的地址會不會沖突,地址不沖突就不需要去算這些地址。
4286
跟我學PLC ??? 3年前
20條/頁 
 76
76 跳至頁

技術鄰APP
工程師必備
工程師必備
- 項目客服
- 培訓客服
- 平臺客服
TOP
