



九分鐘快速學會使用python實現隨機森林數據訓練和預測(附代碼) 

介紹了一個典型的利用python進行隨機森林訓練和預測數據的代碼,可以幫助大家迅速掌握隨機森林的應用。
310
活潑可男_matlab教學 ??? 1年前
十分鐘掌握matlab實現隨機森林代碼(新手超友好!) 
介紹了使用matlab實現隨機森林的詳細步驟和具體的程序,希望對大家有所幫助。
416
活潑可男_matlab教學 ??? 1年前
十分鐘快速掌握決策樹與隨機森林原理 
介紹了決策樹和隨機森林的計算原理,希望對大家有所幫助,大家有問題也歡迎在評論區當中提出。
230
活潑可男_matlab教學 ??? 1年前
自動機器學習綜述 
它目前只支持以下算法:隨機森林(分類和回歸)、線性回歸和邏輯回歸。 Apache MXNet的模型服務器用于服務從MXNet或Open Neural Network Exchange (ONNX)導出的深度學習模型。
2338
駕駛哥 ??? 4年前
機器學習模型的集成方法總結:Bagging, Boosting, Stacking, Voting, Blending 
隨機森林是利用Bagging的最著名和最常用的模型之一。它由大量的決策樹組成,這些決策樹作為一個整體運行。它使用Bagging和特征隨機性的概念來創建每棵獨立的樹。每棵決策樹都是從數據中隨機抽取樣本進行訓練。在隨機森林中,我們最終得到的樹不僅接受不同數據集的訓練,而且使用不同的特征來預測結果。Bagging通常有兩種類型——決策樹的集合(稱為隨機森林)和決策樹以外的模型的集合。
2373 1
牛頓家的計算機 ??? 3年前
【技術】DTEmpower核心功能技術揭秘(7) - ROD基于回歸分析的異常點檢測技術 
② 建模方法:根據圖5所示的建模流程,采用隨機森林算法進行模型訓練,然后對比在激活ROD和不激活ROD的情況下模型的精度指標。圖5 基于DTEmpower軟件平臺的風機測點結構應力快速評估建模方案,方案中選取2種常見算法進行模型的訓練。
2080
天洑軟件 ??? 3年前
17個機器學習的常用算法
常見的算法包括:分類及回歸樹(Classification And Regression Tree, CART), ID3 (Iterative Dichotomiser 3), C4.5, Chi-squared Automatic Interaction Detection(CHAID), Decision Stump, 隨機森林(Random Forest), 多元自適應回歸樣條(MARS)以及梯度推進機
2385 1
王者歸來123 ??? 3年前
五分鐘學會python實現決策樹和隨機森林數據訓練和預測(詳細講解代碼,包教包會!) 
介紹了一個python實現決策樹數據擬合并進行預測的案例,希望對大家有所幫助,代碼放在課程附件當中,歡迎大家在評論區提出問題討論。
438
活潑可男_matlab教學 ??? 1年前
理論加案例,一文讀懂數據分析中的分類建模 
集成學習算法里,RandomForest隨機森林算法很有代表性,它最顯著的優點是抗過擬合能力強。 所謂過擬合,指的是模型在訓練數據上表現非常好,精度很高。但遇到新數據,精度就崩了。 除了抗過擬合,隨機森林算法的魯棒性也很強。如果數據存在異常值,模型也不會有明顯的精度下降。 當然凡事都有兩面性。隨機森林算法的缺點之一就是模型訓練過程的計算量大,而且得到的模型是一個黑箱模型。
2296
天洑軟件 ??? 11月前
機器學習回歸模型相關重要知識點總結 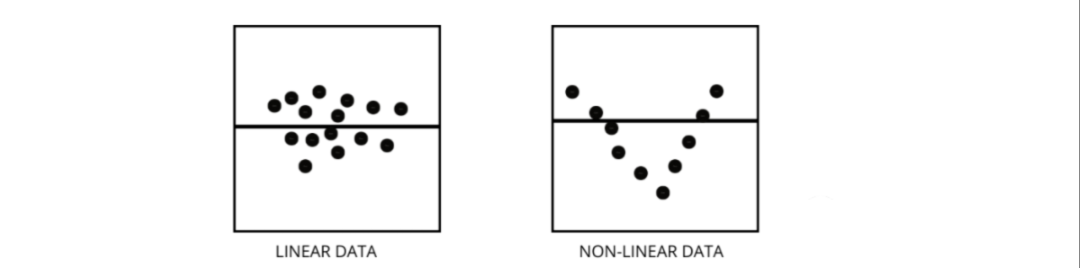
如果數據點隨機散布在沒有圖案的線上,那么線性回歸模型非常適合數據,否則我們應該使用非線性模型。 3、如何區分線性回歸模型和非線性回歸模型?兩者都是回歸問題的類型。兩者的區別在于他們訓練的數據。線性回歸模型假設特征和標簽之間存在線性關系,這意味著如果我們獲取所有數據點并將它們繪制成線性(直線)線應該適合數據。 非線性回歸模型假設變量之間沒有線性關系。
2160
牛頓家的計算機 ??? 3年前
【技術】DTEmpower核心功能技術揭秘(2) - AIOD智能異常點檢測技術 
該方法采用了Random Forest隨機森林、GBDT(Gradient Boosting Decision Tree)梯度提升樹、ExtraTrees極限隨機樹和基于Bagging的BaggingDeFo共4種算法進行實驗。圖4 針對某工業數據集,在DTEmpower軟件平臺上搭建回歸分析的建模方案。使用AIOD智能異常點檢測技術進行異常點檢測和刪除。
2255 3 2
天洑軟件 ??? 4年前
XGBoost 工作原理詳解
XGBoost 工作原理詳解傳統機器學習模型(如決策樹和隨機森林)易于解釋,但在復雜數據集上往往難以保證準確性。XGBoost(Extreme Gradient Boosting 的縮寫)是一種先進的機器學習算法,專為實現高效性、快速性和高性能而設計。
1983 1
仿真資料吧 ??? 4月前
【新聞】DTEmpower核心功能技術揭秘(5) - AIAgent模塊 
② 建模和實驗方法:采用圖2所示的建模方法,對輸入和輸出之間的映射關系進行回歸分析建模。該方法采用了Random Forest隨機森林、GBDT(Gradient Boosting Decision Tree)梯度提升樹、多項式擬合和AIAgent訓練算法進行回歸分析建模。然后對比不同模型的R2和NRMSE指標。
2130
天洑軟件 ??? 3年前
【技術】天洑數據建模實施案例集錦(3)- 風力機輪轂強度快速評估 
建模方法和結果:圖1所示的建模方法采用了GBDT、隨機森林和AIAgent等多種算法進行回歸分析,最終選取精度最高的模型;圖1 基于DTEmpower軟件平臺的輪轂強度分析建模流程和結果。首先利用AIPOD的智能采樣功能計算生成數據集,然后在DTEmpower中進行建模分析3.
2193
天洑軟件 ??? 3年前
諾貝爾物理化學獎全給了AI,你不試試這個機器學習軟件? 
展(無)開(聊)說,模型訓練過程分別基于對數正態函數分布、廣義帕累托分布和H2018模型三種函數形式,擬合算法采用了DTEmpower內置的隨機森林、多項式、K近鄰回歸和多層感知器四種機器學習算法。訓練完成后,再采用納什效率系數(Nash efficiency coefficient)等多個參數對模型的準確性進行評判。明白了吧?別緊張,不明白沒事(我也不懂。
2339
天洑軟件 ??? 1年前
Abaqus中材料參數隨機場實現 
*cov;
% rxy=0;
% rou=[1 rxy
% rxy 1];
rou=eye(size(mu,1));
L1=chol(rou); %L1==rou
% 讀取隨機場單元中心點橫坐標x和縱坐標y
mLem=length(Coord);
% ACF=1 指數型(SNX); ACF=2 高斯型(SQX); ACF=3 二階自回歸型(CSX); ACF=4 指數余弦型
5655 28 11
文化人不大聰明 ??? 4年前
基于深度學習的電阻抗、電磁與電容層析成像方法研究 
2.2 掩碼設計與多形狀目標插入策略每一組樣本數據通過向背景模型中插入 1~4 個形狀隨機的電導率擾動區域構建,目標形狀包括: circle(圓形) triangle(等邊三角形) half_circle(半圓區域,模擬邊界病灶/非對稱結構)每個目標形狀滿足以下原則: 隨機位置:確保中心不越出場域邊界; 隨機大小:半徑范圍在 [0.1, 0.3]
2464 2 1
320科技工作室 ??? 7月前
徑向基函數內核 – 機器學習 
? 核化嶺回歸:在回歸任務中,RBF核可用于執行核化嶺回歸,從而允許模型捕獲特征和目標變量之間的非線性關系。? 聚類:RBF內核還可以用于內核化聚類算法,例如頻譜聚類,它有助于捕獲數據的局部結構,以便將相似的數據點分組在一起。? 降維:在流形學習和非線性降維技術中,如t分布式隨機鄰域嵌入(t-SNE),RBF內核用于定義高維空間中數據點之間的相似性。
3612 23 8
仿真資料吧 ??? 1年前
【篇三】生物醫藥領域發文難?(CADD、ROSETTA、多組學)一區SCI墊腳石已備好! 
如轉錄組學,代謝組學常用組學數據庫介紹,如TCGA,PathBank,HMDB,KEGGPython批量處理組學數據-歸一化處理,差異分析,相關性分析生物功能分析:GO 功能分析、代謝通路富集、分子互作等基于轉錄組學的差異基因篩選,疾病預測基于差異基因,聯合代謝組學分析疾病分子發生機制? 組學數據可視化,如火山圖,t-SNE降維,代謝通路網絡分析? 組學特征(基因,蛋白,代謝物)選擇(隨機森林分析
2427
。_4485 ??? 3年前
什么是徑向基函數神經網絡? 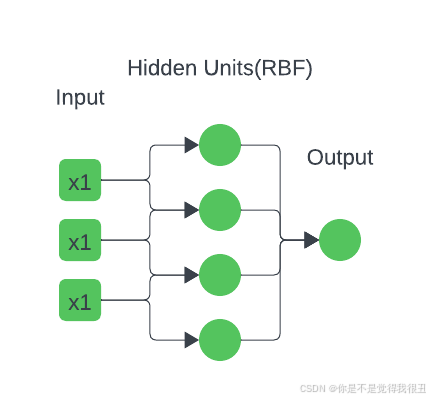
第 1 步:選擇中心 中心選擇技術:中心可以從訓練數據集中隨機選擇,也可以通過應用 k-means 聚類等技術來選擇。 K-Means 聚類:在這種廣泛使用的中心選擇技術中,這些聚類的中心被用作 RBF 神經元的中心,該技術將輸入數據分組為 k 組。
2692 2 1
仿真資料吧 ??? 1年前
20條/頁 
跳至頁

技術鄰APP
工程師必備
工程師必備
- 項目客服
- 培訓客服
- 平臺客服
TOP
