Python爬蟲(chóng)實(shí)戰(zhàn)之微信實(shí)時(shí)爬取電影咨詢(xún)
1. 撩妹起源
俗話(huà)說(shuō)的好:少壯不撩妹,長(zhǎng)大徒傷悲啊!

說(shuō)的很對(duì),但是在這個(gè)撩妹的時(shí)代,要想成功把到妹,還真得花點(diǎn)心思才行啊。每次和妹子約會(huì),妹子有時(shí)就會(huì)問(wèn):最近有啥好看的電影沒(méi)?對(duì)于妹子的提問(wèn),回答要么就是不知道,要么就是自己去查app了,覺(jué)得這樣有時(shí)候就缺少了一些互動(dòng)的樂(lè)趣了。
于是就在想,如果有個(gè)能爬取電影咨詢(xún)并能自動(dòng)回復(fù)的東東是不是覺(jué)得有點(diǎn)小驚喜呢?
效果如如下:

(后面有完整的效果)
也是前一陣閑來(lái)無(wú)事,想到這就搞了個(gè)簡(jiǎn)單的小工具,實(shí)現(xiàn)了在微信上實(shí)時(shí)爬取網(wǎng)站電影咨詢(xún)的功能。這樣子,以后就可以偶爾給給妹子來(lái)個(gè)小驚喜,沒(méi)準(zhǔn)兒就投懷送抱了呢。哈哈,博主也是開(kāi)玩笑,其實(shí)就是覺(jué)得好玩,擼起袖子就是一頓敲。
2. 功能分析
好了,讓我們看看是怎么個(gè)一回事。
網(wǎng)站電影的信息來(lái)源于豆瓣,都說(shuō)豆瓣評(píng)分很公正客觀,所以就選了這個(gè)作為目標(biāo)源了。
目標(biāo)功能:
用戶(hù)輸入任何帶有電影字樣的話(huà)(如:看電影),自動(dòng)跳轉(zhuǎn)到頁(yè)面,提供 所有電影分類(lèi)供用戶(hù)選擇。
用戶(hù)選擇任意一個(gè)類(lèi)型后,分別反饋給用戶(hù)按熱度、時(shí)間、評(píng)論順序排列的三份前十電影表單(電影名+評(píng)分)。
用戶(hù)根據(jù)提供的電影,輸入任意一個(gè)電影名后,將反饋給用戶(hù)關(guān)于該電影的相關(guān)詳細(xì)信息表單。
要求用戶(hù)可以再次輸入任意電影類(lèi)型去搜其它電影或者此類(lèi)型的任意其它電影。
網(wǎng)站頁(yè)面分析:
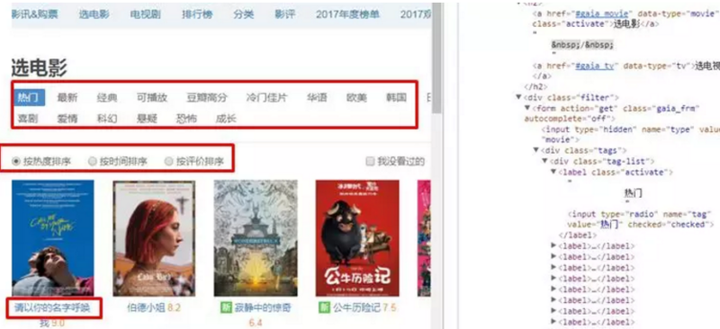
博主看到,這個(gè)頁(yè)面的這些電影類(lèi)型都是動(dòng)態(tài)的信息(紅色框),因此不能使用常規(guī)的request方法舒服的爬取了,這里將使用Selenium自動(dòng)化測(cè)試工具來(lái)解決動(dòng)態(tài)頁(yè)面的爬取(之后會(huì)開(kāi)一篇分享Selenium如何使用)。

這是點(diǎn)擊電影進(jìn)去后看到的詳細(xì)信息,這些信息是靜態(tài)的,在源碼中有很好的體現(xiàn),因此詳細(xì)信息的爬取使用前幾篇分享過(guò)的request方法解析,request方法詳見(jiàn)下面:
Python從零學(xué)爬蟲(chóng) Python爬蟲(chóng)之urllib庫(kù)—進(jìn)階篇
頁(yè)面抓取分析:
抓取信息博主使用了Selenium中的Xpath定位動(dòng)態(tài)數(shù)據(jù),以及BeautifulSoup的方法定位靜態(tài)數(shù)據(jù),方法很多種不唯一,只供參考(后續(xù)馬上開(kāi)一篇?dú)w納所有爬取信息的方法)。
微信對(duì)話(huà):
與微信互動(dòng)的方面,就使用簡(jiǎn)單的接口模塊itchat實(shí)現(xiàn),鏈接里面有詳細(xì)的api介紹,http://itchat.readthedocs.io/...
好了,到此基本的功能實(shí)現(xiàn)方法有了一個(gè)概況,下面看看源碼。由于篇幅問(wèn)題,博主這里貼上部分主要源碼,完整源碼可以在以下鏈接下載:https://github.com/xiaoyusmd/...
3. 源碼分析
電影概況信息(電影名+評(píng)分):
def browser_action_general_info(self, type_command):
"""
chrome browser acts to crawl the general info to users (movie name, score)
:param type_command:
:return:
"""
self.driver.get(self.url_category)
sleep(1)
# 點(diǎn)擊選擇的電影類(lèi)型
for num in range(0, len(movie_category)):
if type_command == movie_category[num]:
self.driver.find_element_by_xpath('//*[@id="content"]/div/div[1]/div/div[2]/div[1]'
'/form/div[1]/div[1]/label[{}]'.format(num+1)).click()
sleep(1)
# 進(jìn)行電影概況信息爬取
self.browser_crawl_general_info()
# 返回一個(gè)包括所有順序排列的電影名及評(píng)分,供后邊查電影具體信息查找用
return movie_info_hot + movie_info_time + movie_info_comment
def browser_crawl_general_info(self):
"""
crawl the general info from douban webstie
:return:
"""
# 清空順列排列的列表,為用戶(hù)下一次操作準(zhǔn)備
del movie_info_hot[:]
del movie_info_time[:]
del movie_info_comment[:]
for num in range(1, 4):
# 分別點(diǎn)擊hot, time, comment順序排列
self.driver.find_element_by_xpath('//*[@id="content"]/div/div[1]/div/div[2]/div'
'[1]/form/div[3]/div[1]/label[{}]/input'.format(num)).click()
sleep(1)
# 分別獲取三組順序排列的前十個(gè)電影名和評(píng)分
for counter in range(1, 11):
if num == 1:
movie_info_hot.append(self.get_movie_general_info(counter))
elif num == 2:
movie_info_time.append(self.get_movie_general_info(counter))
elif num == 3:
movie_info_comment.append(self.get_movie_general_info(counter))
else:
pass
# 對(duì)數(shù)據(jù)進(jìn)行清洗整理
self.clean_general_info()
這里使用了Chrome瀏覽器作為模擬對(duì)象進(jìn)行爬取,由于瀏覽器有點(diǎn)慢,操作間隙加了一些延遲,不然反應(yīng)不過(guò)來(lái)。如果追求速度,也可以使用PhantomJS來(lái)代替Chrome。
使用Selenium的xpath定位對(duì)象,利用鼠標(biāo)點(diǎn)擊事件完成動(dòng)態(tài)操作。
電影詳細(xì)信息操作:
def browser_action_detail_info(self, counter, movie_name):
"""
chrome browser acts to crawl the detail info for users
:param counter:
:param movie_name:
:return:
"""
movie_click_num = 0
# click the type of movie
# 點(diǎn)擊上次用戶(hù)選擇的電影類(lèi)型
for num in range(0, len(movie_category)):
if command_cache[0] == movie_category[num]:
self.driver.find_element_by_xpath('//*[@id="content"]/div/div[1]/div/div[2]/div[1]'
'/form/div[1]/div[1]/label[{}]'.format(num+1)).click()
sleep(1)
# 點(diǎn)擊選擇用戶(hù)選擇的電影所在順序排列
self.driver.find_element_by_xpath('//*[@id="content"]/div/div[1]/div/div[2]/div'
'[1]/form/div[3]/div[1]/label[{}]/input'.format(counter)).click()
sleep(1)
if counter == 1:
for x in range(0, len(movie_info_hot)):
if movie_name in movie_info_hot[x]:
movie_click_num = x + 1
elif counter == 2:
for x in range(0, len(movie_info_time)):
if movie_name in movie_info_time[x]:
movie_click_num = x + 1
else:
for x in range(0, len(movie_info_comment)):
if movie_name in movie_info_comment[x]:
movie_click_num = x + 1
# 點(diǎn)擊電影名稱(chēng)進(jìn)入詳細(xì)頁(yè)面,記錄詳細(xì)頁(yè)面的url
movie_detail_url = self.driver.find_element_by_xpath('//*[@id="content"]/div/div[1]/div/div[4]/div/a[{}]'
.format(movie_click_num)).get_attribute('href')
return movie_detail_url
根據(jù)用戶(hù)輸入的電影名,查找其在詳細(xì)列信息列表movie_info_all(三個(gè)順序排列列表hot, time,
comment的順序extend總和)的位置進(jìn)而定位電影名在哪個(gè)排列列表中里面,然后點(diǎn)擊進(jìn)去獲得該電影的url
電影詳細(xì)信息頁(yè)面下載:
@staticmethod
def download_detail_info_html(url_target):
"""
download douban target html
:param url_target:
:return:
"""
try:
response = urllib.request.Request(url_target, headers=headers)
result = urllib.request.urlopen(response)
html = result.read().decode('utf-8')
# 返回下載的網(wǎng)頁(yè)html,以供下一步進(jìn)行數(shù)據(jù)提取
return html
except urllib.error.HTTPError as e:
if hasattr(e, 'code'):
print(e.code)
except urllib.error.URLError as e:
if hasattr(e, 'reason'):
print(e.reason)
根據(jù)上面返回的電影名url進(jìn)行request下載,并返回下載的html。
由于不是海量數(shù)據(jù)爬取,也沒(méi)加入代理IP池等反爬技術(shù)。
電影詳細(xì)信息解析(字段):
@staticmethod
def parse_detail_info(html_result):
"""
parse the html downloaded
:param html_result:
:return:
"""
# 清空詳細(xì)信息列表
del movie_detail_info[:]
# 定義詳細(xì)信息字段
movie_name = ''
actor_name_list = '主演: '
director_name = '導(dǎo)演: '
movie_type = '類(lèi)型: '
movie_date = '上映日期: '
movie_runtime = '片長(zhǎng): '
soup = BeautifulSoup(html_result, 'lxml')
# 用BeautifulSoup方法從下載頁(yè)面中提取字段信息
movie_name = movie_name + soup.find('span', property='v:itemreviewed').string.strip()\
+ soup.find('span', class_='year').string.strip()
director_name = director_name + soup.find('a', rel='v:directedBy').string.strip()
for x in soup.find_all('a', rel='v:starring'):
actor_name_list = actor_name_list + x.string.strip() + '/'
for x in soup.find_all('span', property='v:genre'):
movie_type = movie_type + x.string.strip() + '/'
for x in soup.find_all('span', property='v:initialReleaseDate'):
movie_date = movie_date + x.string.strip() + '/'
movie_runtime = movie_runtime + soup.find('span', property='v:runtime').string.strip()
# 將所有字段信息字符串放入詳細(xì)信息列表中
movie_detail_info.append(movie_name)
movie_detail_info.append(director_name)
movie_detail_info.append(actor_name_list)
movie_detail_info.append(movie_type)
movie_detail_info.append(movie_date)
movie_detail_info.append(movie_runtime)
在函數(shù)體開(kāi)頭清空movie_detail_info,以準(zhǔn)備用戶(hù)下次的操作。
根據(jù)提供的html進(jìn)行詳細(xì)信息字段的解析,將各個(gè)字段字符串放進(jìn)movie_detail_info大列表中。
Wehchat微信數(shù)據(jù)交換接口:
@itchat.msg_register(itchat.content.TEXT, itchat.content.PICTURE)
def simple_reply(msg):
global movie_info_all
# 接受用戶(hù)任意包含“電影”的字樣,跳轉(zhuǎn)到指定頁(yè)面等待
if u'電影' in msg['Text']:
douban_object.browser_hotopen()
douban_object.cvt_cmd_to_ctgy_url(msg['Text'])
movie_category_option = ' '.join(douban_crawl.movie_category)
itchat.send_msg('----請(qǐng)選擇一種類(lèi)型----\n' + movie_category_option, msg['FromUserName'])
# 接受用戶(hù)的電影類(lèi)型輸入,并執(zhí)行概況信息爬取,然后反饋給用戶(hù)
elif msg['Text'] in douban_crawl.movie_category:
itchat.send_msg('正在查找' + msg['Text'] + '電影...', msg['FromUserName'])
del douban_crawl.command_cache[:]
douban_crawl.command_cache.append(msg['Text'])
# 進(jìn)行概況信息爬取,并將所有排列列表擴(kuò)展到一起
movie_info_all = douban_object.browser_action_general_info(msg['Text'])
itchat.send_msg('----按熱度排序----\n' + '\n' + '\n'.join(douban_crawl.movie_info_hot),
msg['FromUserName'])
itchat.send_msg('----按時(shí)間排序----\n' + '\n' + '\n'.join(douban_crawl.movie_info_time),
msg['FromUserName'])
itchat.send_msg('----按評(píng)論排序----\n' + '\n' + '\n'.join(douban_crawl.movie_info_comment),
msg['FromUserName'])
# 接受用戶(hù)的電影名的選擇,并進(jìn)行指定電影的詳細(xì)字段爬取,然后返回給用戶(hù)
else:
search_num = 0
for x in movie_info_all:
if msg['Text'] in x:
itchat.send_msg('正在查找' + msg['Text'] + '...', msg['FromUserName'])
loc = movie_info_all.index(x)
if 0 <= loc < 10:
search_num = 1
elif 10 <= loc < 20:
search_num = 2
else:
search_num = 3
break
url_result = douban_object.browser_action_detail_info(search_num, msg['Text'])
html_result = douban_object.download_detail_info_html(url_result)
douban_object.parse_detail_info(html_result)
itchat.send_msg('\n\n'.join(douban_crawl.movie_detail_info), msg['FromUserName'])
movie_detail_info等的一些列表都是用了join方法字符串化了,并用n隔開(kāi)。
以上就是大部分的核心源碼了,寫(xiě)的有點(diǎn)糙,歡迎大家一起討論和指正。
4. 功能效果圖
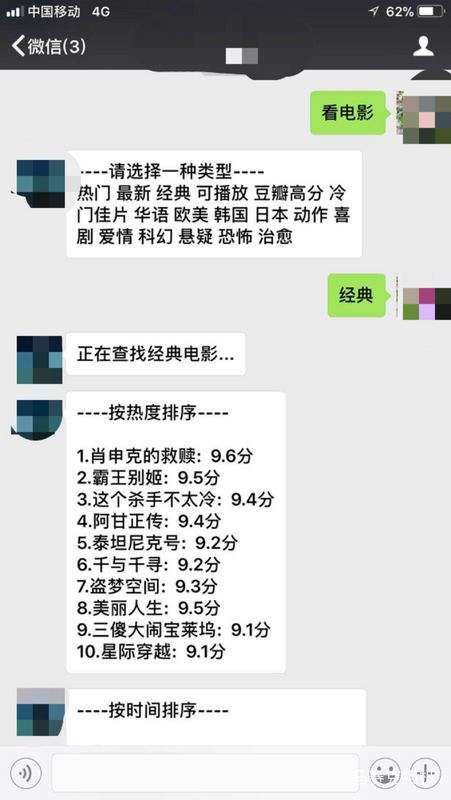
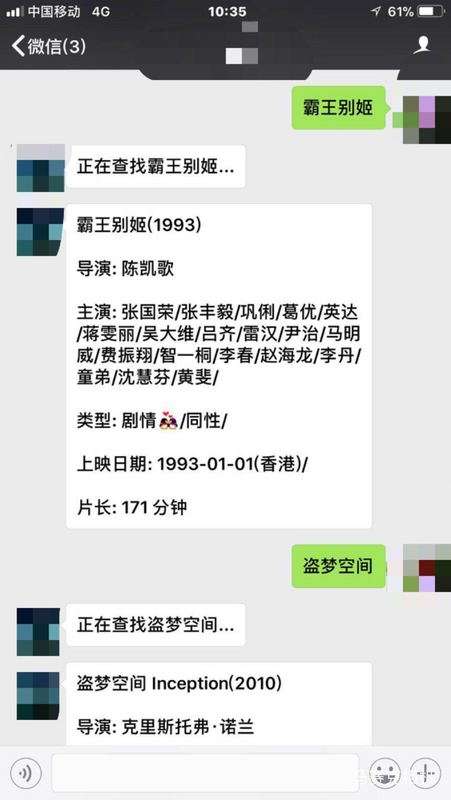
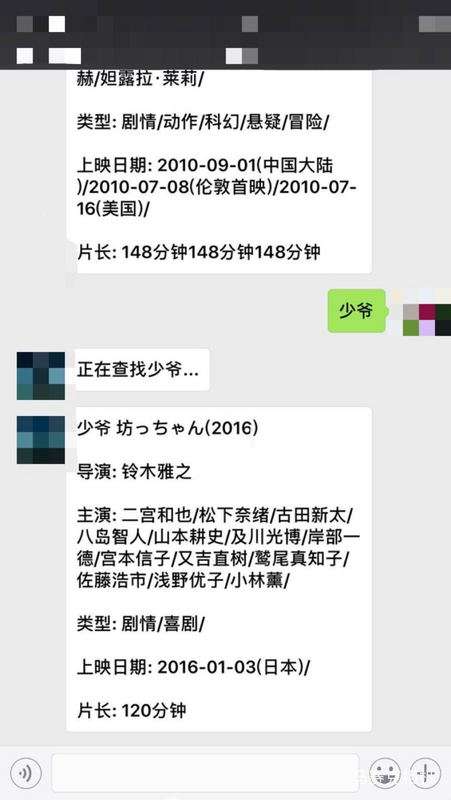
5.總結(jié)歸納
模塊使用
使用Selenium工具進(jìn)行動(dòng)態(tài)操作
使用request進(jìn)行相應(yīng)靜態(tài)請(qǐng)求下載
使用Selenium的xpath進(jìn)行數(shù)據(jù)定位和提取
使用BeautifulSoup進(jìn)行數(shù)據(jù)提取
使用itchat完成微信對(duì)話(huà)數(shù)據(jù)交互
改進(jìn)和完善
用戶(hù)完成操作后一定時(shí)間內(nèi)無(wú)反應(yīng)瀏覽器自動(dòng)關(guān)閉
多人同時(shí)發(fā)信息的并發(fā)問(wèn)題
發(fā)生網(wǎng)絡(luò)等中斷錯(cuò)誤時(shí)提示給用戶(hù) 將電影的圖片也一起返回給用戶(hù)(現(xiàn)在下載的圖片格式webp)
還有很多地方需要改進(jìn)和完善,在此與大家先分享,僅供參考,更多精彩內(nèi)容后續(xù)分享。
作者:Python數(shù)據(jù)科學(xué)





















工程師必備
- 項(xiàng)目客服
- 培訓(xùn)客服
- 平臺(tái)客服
TOP




