Tensorflow 中的長短期記憶 (LSTM) RNN

?
本文討論了 “循環神經網絡 (RNN) ” 和 “長短期記憶 (LSTM) ” 的概念,以及它們使用 編程語言和必要的庫的實現。
遞歸神經網絡
- 它是最古老的網絡之一,創建于 1980 年代,但當時沒有計算機的計算能力,因此近年來它沒有成為眾人矚目的焦點,由于高生成數據和計算機的高計算能力,它變得非常流行。
- RNN 的主要用途是它非常準確地用于序列和時間序列數據。
- 它是最強大的算法之一,它具有內部存儲器來存儲以前的數據。這是 結構中的主要關鍵特征之一。
- 內部存儲器有助于記住重要的事情,這也允許人們預測接下來會發生什么 RNN 是一個 “反饋” 神經網絡,它在隱藏層有自環。
- RNN 具有短期記憶,它只存儲一小段信息。
 ?
?
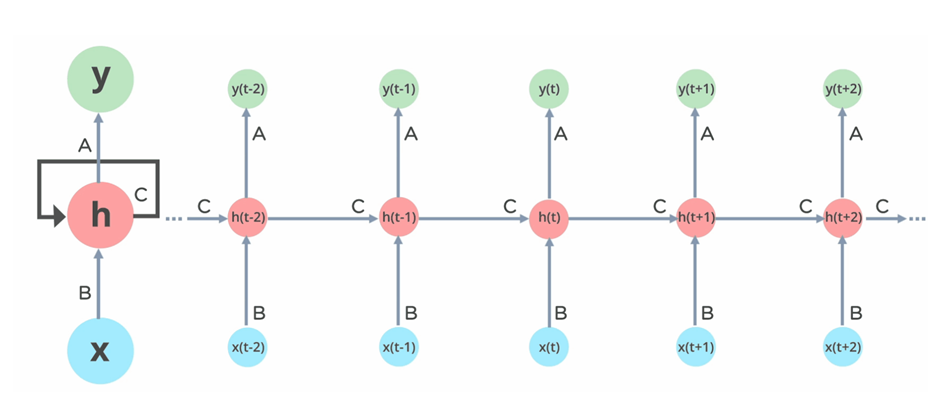
架構或 RNN
上述架構描述了我們可以觀察到 input(x) 傳遞到隱藏層 (c) 的 RNN 功能,其中隱藏層具有自環來存儲內存,并且信息傳遞給輸出層。在這里,隱藏層的功能將是下一組輸入,以便隱藏層充當短期記憶并將信息帶到下一組層。
RNN 的缺點
- 計算速度會很慢
- RNN 網絡只承載短期信息,長期信息不能被納入。
- 梯度問題趨于消失(Value 太小,模型停止學習)
長短期記憶
為了克服 RNN 中遇到的缺點,科學家發明了一項名為“長短期記憶”的發明。 是 RNN 的子項,它可以存儲長期信息并克服梯度消失的缺點。
1. 忘記門
它負責保留信息或忘記信息,因此對其應用 sigmoid 激活函數,如果它是 0(忘記信息)或 1(保留信息),則輸出范圍為 0-1。
![]() ?
?
2. 輸入門
它負責表達輸入所攜帶的新信息的重要性,在這里我們將應用兩個激活函數 sigmoid 和 tanh。sigmoid 功能是保留或丟棄信息,而 tanh 功能是從細胞狀態中減去信息或向細胞狀態添加新信息。
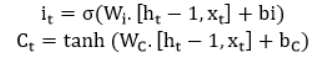 ?
?
3. 輸出門
根據我們獲得的信息,我們將句子作為填空函數提供給輸出門,根據它感知到的信息將輸出結果
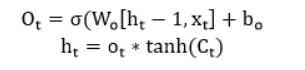 ?
?
導入庫和數據集
庫使我們能夠非常輕松地處理數據并使用一行代碼執行典型和復雜的任務。
- – 該庫有助于以 2D 數組格式加載數據幀,并具有多種功能可以一次性執行分析任務。
- – Numpy 數組速度非常快,可以在很短的時間內執行大型計算。
- – 此庫用于繪制可視化效果。
- NLTK – 自然語言工具包是一個非常方便的工具,用于將原始文本轉換為已處理的文本,以便將其輸入到機器學習模型中。
- – 這是一個用于機器學習和人工智能的開源庫,并提供一系列功能以通過單行代碼實現復雜的功能。
- Python3 語言
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from tensorflow import keras
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
|
第 2 步:現在使用 pandas 數據幀加載數據。我們將在本文中使用牛奶生產數據,您可以從 .
- 蟒
df = pd.read_csv('monthly_milk_production.csv',
index_col='Date',
parse_dates=True)
df.index.freq = 'MS'
|
現在,讓我們通過打印數據集的前五行來檢查數據集是否已正確加載。
- 蟒
df.head()
|
輸出:
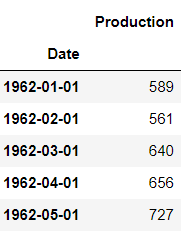 ?
?
數據集的前五行
第 4 步:現在繼續對數據集執行 EDA 分析。
- Python3 語言
# Plotting graph b/w production and date
df.plot(figsize=(12, 6))
|
輸出:
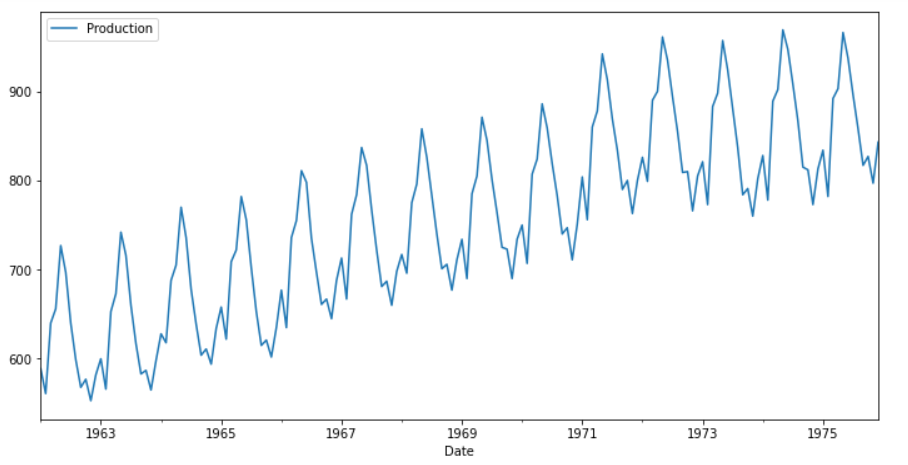 ?
?
牛奶產量隨時間變化的趨勢
步驟 5:時間序列數據的。
- Python3 語言
from statsmodels.tsa.seasonal import seasonal_decompose
results = seasonal_decompose(df['Production'])
results.plot()
|
輸出:
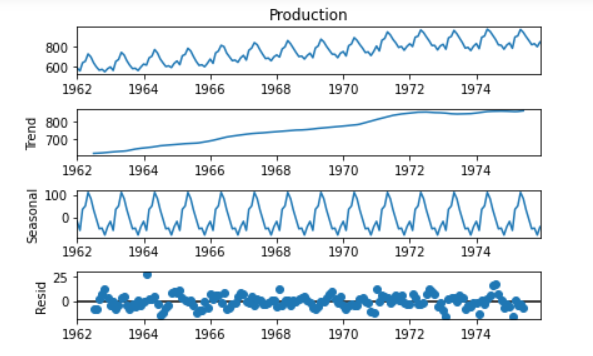 ?
?
所提供數據中的“季節性”、“趨勢”和“殘差”圖表
第 6 步:- 將數據分為訓練和測試。
- 蟒
train = df.iloc[:156]
test = df.iloc[156:]
|
第 7 步:擴展我們的數據以快速準確地執行計算。
- Python3 語言
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(train)
scaled_train = scaler.transform(train)
scaled_test = scaler.transform(test)
|
第 8 步:處理時間序列生成。
- Python3 語言
from keras.preprocessing.sequence import TimeseriesGenerator
n_input = 3
n_features = 1
generator = TimeseriesGenerator(scaled_train,
scaled_train,
length=n_input,
batch_size=1)
X, y = generator[0]
print(f'Given the Array: \n{X.flatten()}')
print(f'Predict this y: \n {y}')
# We do the same thing, but now instead for 12 months
n_input = 12
generator = TimeseriesGenerator(scaled_train,
scaled_train,
length=n_input,
batch_size=1)
|
步驟9: 現在,讓我們使用 TensorFlow API 定義模型的架構。
- Python3 語言
# define model
model = Sequential()
model.add(LSTM(100, activation='relu',
input_shape=(n_input, n_features)))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')
model.summary()
model.fit(generator, epochs=5)
|
輸出:
 ?
?
LSTM 模型的架構
第 10 步:輸出準確率
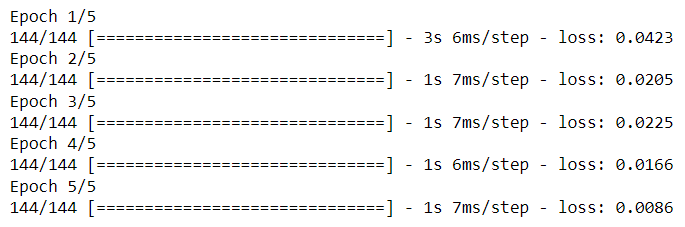 ?
?
LSTM 模型的訓練進度
?





















工程師必備
- 項目客服
- 培訓客服
- 平臺客服
TOP




