機器學習 |使用 Python 的多元線性回歸

?
線性回歸是預測分析的基本常用方法。它是一種用于對因變量和一個自變量之間的關系進行建模的統計方法。 多元線性回歸只是它的擴展版本。它嘗試對兩個或多個特征之間的關系進行建模,以擬合線性方程來預測一個因變量。
多元線性回歸的步驟
執行多元線性回歸的步驟幾乎與簡單線性回歸的步驟相似 d不同 在評估中。我們可以使用它來找出哪個因素對預測輸出的影響最大,以及不同的變量如何相互關聯。
多元線性回歸的方程為:
y=β0+β1X1+β2X2+?+βnXn?
- y是因變量
- X1,X2,?XnX1?,X2?,?Xn?是自變量
- β0β0?是截距
- β1,β2,?βnβ1?,β2?,?βn?是斜率
該算法的目標是找到可以根據自變量預測值的最佳擬合線方程。回歸模型從數據集中學習一個函數(具有已知的 X 和 Y 值),并使用它來預測未知 X 的 Y 值。
使用虛擬變量處理分類數據
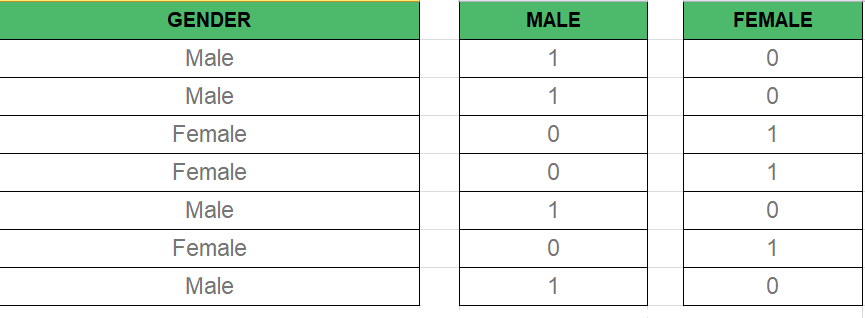
在多元回歸模型中,我們經常會遇到分類數據,例如性別(男性/女性)、位置(城市/農村)等。由于回歸模型通常需要數字輸入,因此必須將分類數據轉換為可用形式。
這就是 Dummy Variables 發揮作用的地方。虛擬變量是二進制變量(0 或 1),表示每個類別的存在或不存在。例如:
- 男性:如果男性為 1,否則為 0
- 女性:如果女性為 1,否則為 0
 ?
?
在多個類別的情況下(例如,顏色:“紅色”、“藍色”、“綠色”),我們為每個類別創建一個虛擬變量,排除一個以避免多重共線性(下面解釋)。此過程稱為 one-hot encoding,它將分類變量轉換為適合回歸模型的格式。
多元線性回歸中的多重共線性
在構建多元線性回歸模型時,可能會出現多重共線性。當兩個或多個自變量彼此高度相關時,就會發生這種情況。這使得評估每個變量對因變量的單個貢獻變得困難。
檢測多重共線性包括兩種技術:
- 相關矩陣:檢查自變量之間的相關矩陣是檢測多重共線性的常用方法。高相關性(接近 1 或 -1)表示潛在的多重共線性。
- VIF(方差膨脹因子):VIF 是一種度量,用于量化預測變量相關時估計回歸系數的方差增加多少。高 VIF(通常高于 10)表明多重共線性。
在接下來的章節中,我們將深入學習這些技術
多元回歸模型的假設
就像簡單線性回歸一樣,我們在多元線性回歸中也使用了一些假設:
- 線性度:因變量和自變量之間的關系應該是線性的。
- 同源性:誤差的方差在所有自變量水平上應保持不變。
- 多元正態性:殘差應服從正態分布。
- 無多重共線性:自變量不應高度相關。
在 Python 中實現多元線性回歸模型
我們將使用 California Housing 數據集,其中包括收入中位數、平均房間和目標變量房價等特征。
1. 導入庫
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_california_housing
2. 加載數據集
# Load the California Housing dataset
california_housing = fetch_california_housing()
# Assign the data (features) and target (house prices)
X = pd.DataFrame(california_housing.data, columns=california_housing.feature_names)
y = pd.Series(california_housing.target)
- 從 中獲取 California Housing 數據集。
sklearn.datasets - 數據集包含存儲在 中的特征(例如收入中位數、平均房間數),目標(房價)存儲在 中。
Xy
3. 選擇要可視化的特征
X = X[['MedInc', 'AveRooms']]
選擇兩個特征( 中位數收入 和 平均房間 )以將可視化簡化為兩個維度。MedIncAveRooms
4. Train-Test 拆分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
5. 初始化和訓練模型
model = LinearRegression()
model.fit(X_train, y_train)
6. 做出預測
y_pred = model.predict(X_test)
7. 在 3D 中可視化最佳擬合線
fig = plt.figure(figsize=(10, 7))
ax = fig.add_subplot(111, projection='3d')
ax.scatter(X_test['MedInc'], X_test['AveRooms'], y_test, color='blue', label='Actual Data')
x1_range = np.linspace(X_test['MedInc'].min(), X_test['MedInc'].max(), 100)
x2_range = np.linspace(X_test['AveRooms'].min(), X_test['AveRooms'].max(), 100)
x1, x2 = np.meshgrid(x1_range, x2_range)
z = model.predict(np.c_[x1.ravel(), x2.ravel()]).reshape(x1.shape)
ax.plot_surface(x1, x2, z, color='red', alpha=0.5, rstride=100, cstride=100)
ax.set_xlabel('Median Income')
ax.set_ylabel('Average Rooms')
ax.set_zlabel('House Price')
ax.set_title('Multiple Linear Regression Best Fit Line (3D)')
plt.show()
輸出:
 ?
?
可視化多元線性回歸
藍色點表示基于要素(MedInc 和 AveRooms)的實際房價,紅色表面表示多元線性回歸模型預測的最佳擬合平面。此圖顯示了兩個所選特征如何影響預測的房價。
?





















工程師必備
- 項目客服
- 培訓客服
- 平臺客服
TOP




