YOLO v2 – 對象檢測

在速度方面,YOLO 是對象識別領域最好的模型之一,能夠以高達 150 FPS 的速率識別對象并處理幀,適用于小型網絡。然而,就準確率 mAP 而言,YOLO 并不是最先進的模型,但在 PASCAL VOC2007 和 PASCAL VOC 2012 上訓練時,平均精度 (mAP) 相當好,為 63%。然而,當時最先進的 Fast R-CNN 的 mAP 為 71%。
YOLO v2 和 YOLO 9000 由 J. Redmon 和 A. Farhadi 于 2016 年在題為“YOLO 9000:更好、更快、更強”的論文中提出。在 67 FPS 時,YOLOv2 的 mAP 為 76.8%,在 67 FPS 時,它在 VOC 2007 數據集上的mAP 為78.6%,優于更快的 R-CNN 和 SSD 等模型。YOLO 9000 使用 YOLO v2 架構,但能夠檢測到 9000 多個類。然而,YOLO 9000 的 mAP 為 19.7%。
讓我們看看 YOLO v2 的架構和工作:
架構變化與 YOLOv1:
與 Fast R-CNN 等最先進的方法相比,以前的 YOLO 架構存在很多問題。它犯了很多本地化錯誤,而且召回率很低。所以,本文的目標不僅是改善 YOLO 的這些缺點,而且要保持架構的速度。基本 YOLO 中進行了一些增量改進。讓我們在下面討論這些變化:

Darknet-19 簡化版
- 批量歸一化:
- 通過在架構中添加批量歸一化,我們可以提高模型的收斂性,從而加快訓練速度。這也消除了應用其他類型的歸一化的需要,例如沒有過擬合的 Dropout。還觀察到,與基本 YOLO 相比,單獨添加批量歸一化會導致 mAP 增加 2%。
- 高分辨率分類器:
- 以前版本的 YOLO 在訓練期間使用 224 *224 作為輸入大小,但在檢測時,它需要的圖像大小最大為 448*448。這會導致模型調整到新的分辨率,進而導致 mAP 降低。
- YOLOv2 版本在 ImageNet 數據上以更高的分辨率 (448 * 448) 訓練 10 個時期。這讓網絡有時間調整過濾器以獲得更高的分辨率。通過在 448*448 圖像大小上進行訓練,mAP 增加了 4%。
- 將錨框用于邊界框:
- YOLO 使用全連接層來預測邊界框,而不是像 Fast R-CNN、Faster R-CNN 那樣直接從卷積網絡預測坐標。
- 在這個版本中,我們刪除了全連接層,而是添加了錨框來預測邊界框。我們在架構中進行了以下更改:
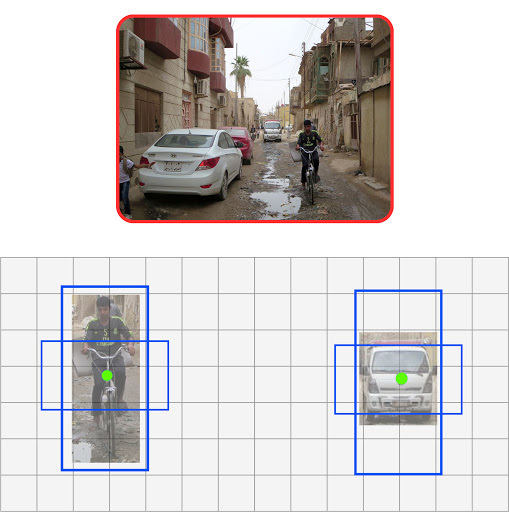
具有 1 個以上錨點的邊界框(將提供更準確的定位)
- 我們刪除了負責預測邊界框的全連接層,并將其替換為錨框預測。

刪除了圖層的 YOLOv1(填充紅色)
- 我們將輸入的大小從 448 * 448 更改為 416 * 416。當我們將其下采樣 32 倍時,這將創建一個大小為 13 * 13 的特征圖。這背后的想法是,對象很有可能位于特征圖的中心。
- 刪除一個池化層以獲得 13 * 13 的空間網絡,而不是 7*7
- 通過這些更改,模型的 mAP 略有降低(從 69.5% 到 69.2%),但召回率從 81% 增加到 88%。
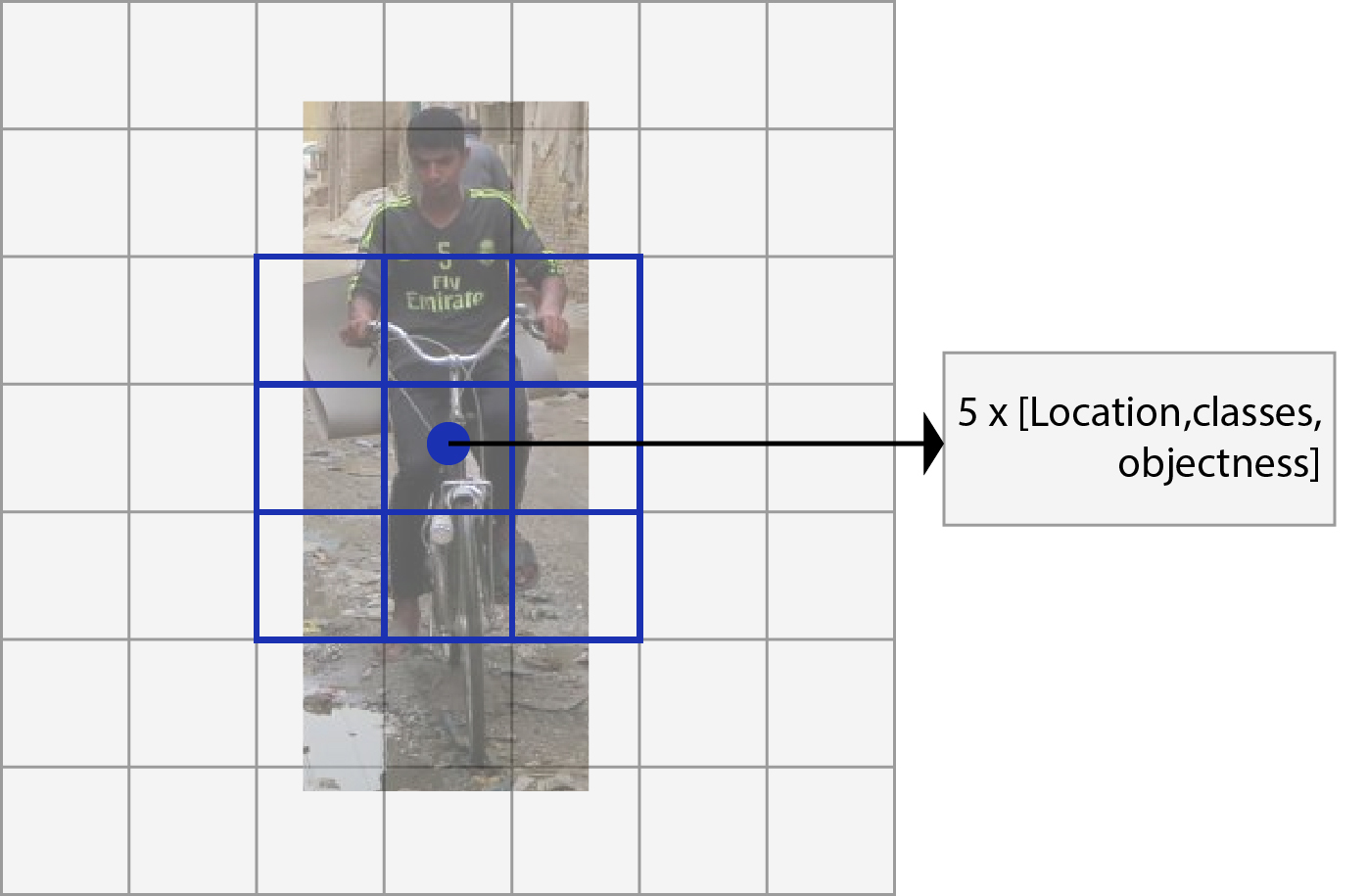
每個對象提案的輸出
- 維度集群:
- 我們需要確定生成的錨點(先驗)的數量,以便它們提供最佳結果。現在讓我們以 K 為例。我們的任務是確定具有最高準確性的圖像的前 K 個邊界框。為此,我們使用 K-means 聚類分析算法。但是,我們不需要最小化歐幾里得距離,而是最大化 IOU 作為該算法的目標。
- YOLO v2 使用 K=5 來更好地權衡算法。從下圖中我們可以得出結論,隨著 K=5 值的增加,精度不會發生顯著變化。
- 基于 K = 5 的基于 IOU 的聚類得到 61% 的 mAP。

維度集群(每個錨點的維度數)與 mAP
- 直接位置問題:
- 以前版本的 YOLO 對位置預測沒有約束,這使得它在早期迭代時不穩定。YOLOv2 預測 5 個參數 (tx、 ty、 tw、 th、 to(客觀性分數))并應用 sigma 函數來約束其值介于 0 和 1 之間。
- 此直接位置約束將 mAP 增加 5%。


- 細粒度功能 :
- 生成 13 * 13 的 YOLOv2 足以檢測大型物體。但是,如果我們想檢測更精細的對象,我們可以修改架構,將前一層 26 * 26 * 512 的輸出更改為 13 * 13 * 2048,并與原始的 13 * 13 * 1024 輸出層連接,使我們的輸出層大小。
- 多尺度訓練:
- YOLO v2 使用 32 步長在 320 * 320 到 608 * 608 的不同輸入大小上進行了訓練。此體系結構為每 10 個批次隨機選擇圖像尺寸。可以在準確性和圖像大小之間建立權衡。例如,圖像大小為 288 * 288 且幀速率為 90 FPS 的 YOLOv2 提供的 mAP 與快速 R-CNN 一樣多。

架構:
YOLO v2 在不同的架構上進行了訓練,例如 VGG-16 和 GoogleNet。該論文還提出了一種稱為 Darknet-19 的架構。選擇 Darknet 架構的原因是它的處理要求比其他架構低 5.58 FLOPS(相比之下,VGG-16 上的 30.69 FLOPS 圖像大小為 224 * 224,定制的 GoogleNet 為 8.52 FLOPS)。Darknet-19 的結構如下:
出于檢測目的,我們替換了此架構的最后一個卷積層,而是每 1024 個濾波器添加三個 3 * 3 卷積層,然后添加 1 * 1 卷積層,其中包含我們需要檢測的輸出數量。
對于 VOC,我們預測 5 個框和 5 個坐標(噸x、 ty、 tw、 th、 to(客觀性分數))每個盒子有 20 個等級。所以過濾器的總數是 125。

Darknet-19 架構
訓練:
YOLOv2 的訓練有兩個目的:
- 對于分類任務,該模型在 ImageNet-1000 分類任務上訓練了 160 個時期,使用 Darknet-19 架構,起始學習率為 0.1,權重衰減為 0.0005,動量為 0.9。此培訓應用了一些標準的數據增強技術。
- 為了進行檢測,我們上面討論過的 Darknet-19 架構中進行了一些修改。該模型在啟動時訓練了 160 個 epoch學習率 10-3,權重衰減為 0.0005,動量衰減為 0.9。在 COCO 和 VOC 上訓練模型的策略相同。
結果和結論:

不同對象檢測框架的結果
YOLOv2 在 PASCAL VOC 和 COCO 上提供了最先進的檢測精度。它可以在不同尺寸上運行,從而在速度和準確性之間進行權衡。在 67 FPS 時,YOLOv2 可以提供 76.8 的 mAP,而在 40 FPS 時,檢測器的精度為 78.6 mAP,優于更快的 R-CNN 和 SSD 等最新模型,同時運行速度明顯快于這些模型。

不同物體檢測的速度與精度曲線
該模型也是 YOLO9000 模型的基礎,該模型能夠實時檢測 9000 多個類。





















工程師必備
- 項目客服
- 培訓客服
- 平臺客服
TOP




