我國是世界上水災頻發且影響范圍較廣泛的國家之一。全國約有35%的耕地、40%的人口和70%的工農業生產經常受到江河洪水的威脅,洪水災害所造成的財產損失居各種災害之首。
因此,制定合理防洪調度策略減輕洪澇災害是我國流域管理的最為緊迫和重要的任務之一。
防洪措施分為工程措施與非工程措施,非工程措施則主要指利用包括建立洪水預報、調度和警報系統。其中,洪水預報與調度一直是頗具挑戰性的課題,及時、準確地進行洪水預報并指導流域水庫洪水調度,不僅可以有效減少洪水對人類生命和財產造成的損失,還可以在保證上、下游洪水安全的情況下,提高洪水資源利用率。今天將從實時洪水預報的角度切入,講解數據同化在一維水動力洪峰預報模型中的應用。
法國的馬爾納河流域屬于喀斯特地貌,地形復雜,這大大增加了在模型中準確設置上游流量和橫流流量的難度。當地洪水預報中心針對馬爾納流域建立了兩個模型,分別為Marne Village model和 Marne Amont Model,見圖1。
這兩個模型雖然可以達到洪水預測的目的,但是其忽略了支流和地形的影響導致模型結果精度不夠。
為了提高預測精度,法國機構CERFACS的工程師將兩個模型合成為一個全局模型,并且使用軟件OpenPALM與Mascaret耦合,將數據同化的算法應用到一維水動力模型中,以此來對原本忽略的喀斯特地貌和各支流帶來的非線性影響進行統一的推演。
注:數據同化(Data Assimilation,下文中以DA表示)是用于減少模型不確定性的方法之一,數據同化能夠結合觀測數據和數值模擬結果推算出最佳估值,具有預報和降低數值模擬的不確定性這兩種優點。
全局模型中上游流量的邊界條件根據五個上游觀測站(Marnay, Louvieres, Villiers, La Crete和Humberville)的數據給定,并且設置了五個橫流,橫流Q1代表Suize河,Q2和Q3代表Rongon流域的Seurre河,Q4代表Mussey河上游支流以及Q5代表Chamouilley河的流量。馬爾納河流域沒有對應的水文降雨-徑流模型,鑒于該流域河流流量的對海洋降雨事件的齊次響應(homogenous response),全局模型中可以用觀測站的監測流量乘以一個系數
Ai( i∈[1,5])
表示橫流流量,達到在模型中包含降雨形成的徑流量的目的。
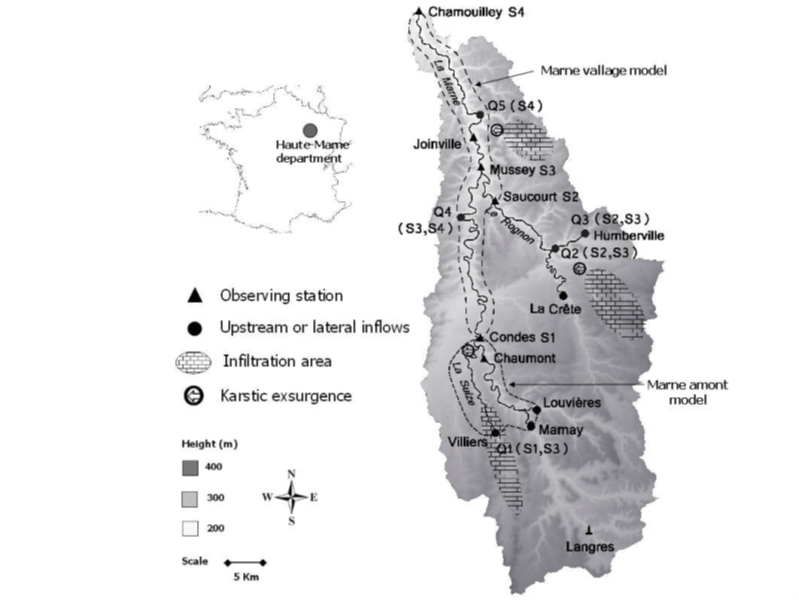
圖1:馬爾納流域地形圖,其中虛線圈出的為全局模型中包含的兩個子模型。黑色三角形代表水利觀測站S1, S2, S3和S4。橫流(黑色圓點)為Q1, Q2, Q3, Q4和Q5,括號里標注的為橫流對應的觀測站。
施加在全局模型中的數據同化算法為擴展卡爾曼濾波法(Extended Kalman Filter)。通過這種數據同化算法,結合2001-2010年法國發生的10次洪水事件的數據,可以對橫流流量進行精確的時變估計,使模型重現12次洪水事件,從而驗證模型的精度。其中,為了防止測量活動中有失誤,全局模型中考慮流量觀測數據的標準差為5 m3/s。對于每次洪水事件,模型都會進行多次循環推演:在循環k中,前8小時先根據觀測數據來預測最佳的Ai值,然后根據預測值Ai計算五個橫流流量(Q1, Q2, Q3, Q4和Q5)并進行24小時的洪水預報模擬。
全局模型分別在無數據同化(free run)和有數據同化(DA)兩種情況下運行,得出的結果表明了將數據同化應用到洪水預報中的益處。表1總結對比了10次洪水事件中,無數據同化和有數據同化兩個模型在每個觀測站的最大預見期(預見期越長,當局開展應急處理的時間越充分)內計算得到的平均納什系數(Nash-Sutcliffe coefficient)。其中納什系數是衡量模型結果好壞的標準,當納什系數的值接近1時,表示模型質量好,結果可信度高;值接近0時,表示模擬結果接近觀測值的平均值水平,即總體結果可信,但過程模擬誤差大;值遠遠小于0時,則模型是不可信的。經過對比可以得知,使用數據同化后,模型的質量得到了顯著提升。
表1:
2001-2010 年期間10 次洪水事件每個觀測站的最大預見期內無數據同化和有數據同化模型模擬得到的平均納什系數
觀測站 |
S1 |
S2 |
Joinville |
S3 |
S4 |
最大預見期 |
+6h |
+10h |
+13h |
+12h |
+21h |
無數據同化(Free run) |
0.61 |
-0.2 |
0.14 |
0.01 |
-1.38 |
有數據同化 (DA) |
0.87 |
0.8 |
0.55 |
0.78 |
0.47 |
無數據同化和有數據同化這兩個模型模擬的2010年12月的主要洪水事件(預見期12 h)的結果對比如圖2所示,相對較粗的線段表示流量數據,對應左邊的縱坐標;較細的線段表示水位數據,對應右邊的縱坐標。藍色點線為Mussey觀測站的觀測數據,總體來說,采用數據同化后模型的預測值(紅色虛線)更接近觀測值,模型得到的流量結果與觀測值的吻合度比水位結果的更高。模型采用的摩擦系數Ks可能是導致此現象的原因。
圖2:
2010年12月預見期12h(Mussey觀測站)的流量(粗曲線)和水位(細曲線)圖:觀測數據(藍色點線),數值模擬無數據同化(free run)(黑色實線),數值模擬有數據同化(DA)(紅色虛線)
全局模型中采用的摩擦系數Ks是在校準10次洪水事件的流量數據過程中得到的平均值。Mussey河段對應的摩擦系數為20,漫灘對應的摩擦系數為13。為了解決摩擦系數引起的不確定性,對于數據同化模型結果比觀測值更高的部分(見圖3,粉色陰影區域),將Mussey河段的摩擦系數改為27,漫灘的摩擦系數改為15;針對數據同化模型結果比觀測值更低的部分(見圖3,藍色陰影區域),河段摩擦系數改為16,漫灘摩擦系數改為9。修正摩擦系數后,模型模擬得到的流量數據結果不變,和原模型的結果一致;而修正后的水位數據和觀測值吻合度明顯提高,峰值相對原模型更接近觀測數據。
圖3:
2010年12月預見期12h(Mussey觀測站)的流量(粗曲線)和水位(細曲線)圖:觀測數據(藍色點線),數值模擬有數據同化(DA)(紅色虛線),數據同化+調整的摩擦系數(綠點)
綜上所示,結果表明數據同化可以有效地減少模型不確定性,并能提高模型預測數據的精度。經過10次洪水事件的推演重現,模型的可靠度得到證明,該模型已經被國家洪水預報中心采用并整合到官方的洪水預報平臺中。
今天主要講述將數據同化算法運用到一維水動力模型進行洪水流量和水位預報的案例。防汛工程中,使用洪水預報模型進行洪水演示,預報洪峰流量、出現時間、最高水位及洪水過程,可以為調節泄洪水位、下游洪水預報及防洪調度提供依據。
更多資訊可登錄格物CAE官方網站
https://cae.yuansuan.cn/
或關注公眾號【遠算云學院】
遠算在bilibili、知乎、技術鄰定期發布課程視頻等內容
敬請關注



























