



支持192核+4块A100---2022年最强大AMD超算工作站GA660M上市 
图灵超算工作站UltraLAB GA660M是2022年12月上市的一款配置双AMD 第4代霄龙EPYC 9004处理器、24通道DDR5 4800内存、最高4块A100/RTX4090系列GPU超算卡、内置海量并行存储于一体、基于办公静音环境环境,这是目前为止CPU核数最多的(高达192核)、多核并行算力强大的图形工作站技术特点: 支持2颗最新AMD 第4代EPYC(霄龙
2707
UltraLAB 3年前
【个人原创】PFC 6.0 二维双轴分级静力加载与动力扰动岩爆模拟代码(含4种工况) 
一套完整的 PFC 6.0 离散元原创算例,专为研究岩石在复杂应力路径下的力学响应及岩爆(Rockburst)现象而设计。代码实现了从初始围压保载到分级径向加载,再到不同波形动力扰动的全过程模拟,逻辑严密,注释清晰。 代码集成了四种极具科研价值的加载工况,用户可一键切换: 分级静力加载:模拟深部岩体开挖过程中的应力重分布。
755
Zyax 1月前
【GPT4.0】惊艳的PFC书写能力!仅四次沟通完成测试需求! 
0 引言 前两天测试了GPT3.5书写PFC命令,结果是一塌糊涂,给人一种不知悔改且极度傲慢的感觉。于是这两天使用GPT4.0来测试一下PFC的书写能力,结果出人意料的好,不到10句的沟通就完成了,颗粒在墙体中自重沉降的算例。因为GPT4.0更加聪明,并且每三小时只有10句话的沟通机会,我上来直奔主题,提出自己大概的需求。
3365 3 1
lobby 3年前
CAD导入的PFC-FLAC3D耦合真三轴冲击 
CAD 复杂建模接口:支持从 CAD 建立复杂三维几何模型,一键导入 PFC 6.0,自动完成 Geometry 到 Clump 的映射与填充,突破软件自带建模工具的形状限制。 PFC-FLAC3D 精准耦合:实现离散元(PFC)与连续介质(FLAC3D)的无缝动力耦合,利用 FLAC3D 模拟远场边界效应,PFC3D 模拟核心破坏区。
1876
Zyax 1月前
64核RISC-V服务器能打了吗? 
多核模式,如果按照38GB/s,那么每个处理器核只能分到0.59GB/s(38GB/64核),还是得8个DDR通道,多线程模式性能才不至于被访存带宽给困住。 我暴力了一把,将64核全部跑起来,颇为壮观! 我在他们的群里找到了这张图片,估计上是边烤机,边开放给开发者使用,加油!!!
2226
Treesa 2年前
智能驾驶域控制器SoC选型 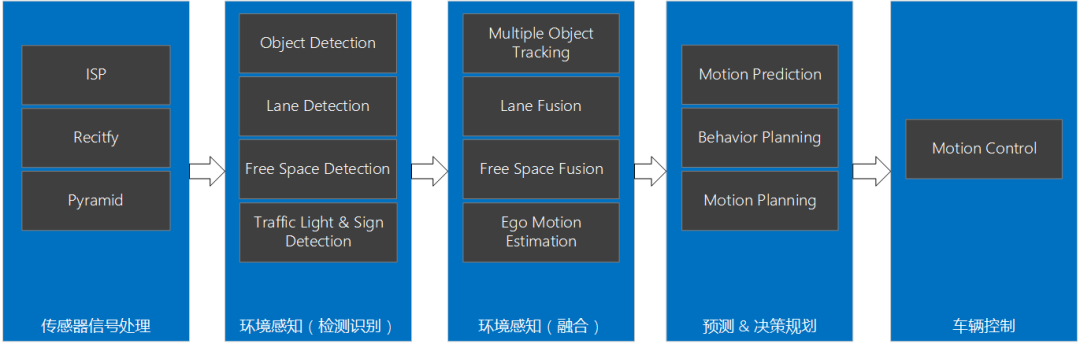
2.2 GPUCPU的功能模块多,适合复杂的运算场景,大部分晶体管用在控制电路和存储上,少部分用来完成运算工作。GPU的控制相对简单,且不需要很大的Cache,大部分晶体管被用于运算,GPU的计算速度因此大增,拥有强大的浮点运算能力。CPU与GPU架构对比示意图当前的多核CPU一般由4或6个核组成,以此模拟出8个或12个处理进程来运算。
2766
驾驶哥 3年前
第一款96核4.8GHz--超频工作站GR450P上市 
硬件特点:§ 采用AMD 锐龙TR PRO 7900WX/锐龙TR 7900X处理器,单CPU最大核数96个,三级缓存L3高达384MB,支持8个内存通道,其高主频、大缓存、大内存带宽特点,是目前单CPU多核并行算力的最强科学计算处理器。
2419 1 1
UltraLAB 2年前
ARM生态的三条新闻,和澎峰科技发布了第一代RISC-V 128核服务器。 
这次算能的SG2042 64核处理器,已经在成为全球首颗多核高性能RISC-V处理器;这次澎峰科技发布的128核RISC-V服务器,已经领先全球同行,并将实现出口创汇。 如果,今天依然还有人愚蠢地认为和到处宣扬“ RISC-V无非是另外一个美国佬主导的生态”,这样的人,可以直接回到原始社会。
2350
Treesa 2年前
CAE云仿真|送你2000核时!先到先得! 
扫码或者点击链接注册登记,送你200算力金(2000核时)~链接:http://t8iw4ulf0hpixn8k.mikecrm.com/XVIHFb4注册成功后即可参与抽奖,我们为您准备了冰墩墩、北鲲云帆布包及小风扇等超值礼品,等你哦!
2606 3
技术邻公告 3年前
6*RTX4090+静音---2022年最强深度学习工作站/集群硬件配置方案 
CNN+ RNN+ 推理 ¥435,000 (六)支持A100+水冷---人工智能推理超级工作站硬件配置推荐 ---逻辑推理超算平台,支持6块A100+水冷静音级完美计算架构:双xeon3代(最大80核),最大6块全速PCIe 4.0 16X全速 A100+海量存储(最大300T)性能出众: FP16算力(6块A100)
3392
UltraLAB 3年前
COMSOL代理模型加速仿真:从"小时级求解"到"毫秒级响应"的工作站硬件配置分析 
组件 配置规格 选型逻辑 CPU Intel Core i9-14900K (24核32线程, 睿频6.0GHz) 高主频加速COMSOL前处理(几何剖分、网格生成);24核支持本地小规模参数扫描 内存 64GB DDR5
1047
UltraLAB 16天前
结构/流体/多物理场/电磁仿真最快最完美工作站集群23v2 
支持电磁仿真计算:HFSS、FEKO支持多物理场耦合:Comsol Multiphysics (一)仿真计算工作站硬件配置推荐硬件配置分类:(1)超频型:具备【多核】+【超频】计算架构,满足小规模仿真计算(2)增强型:配置双Xeon处理器(更多核数)+16通道带宽,满足中等规模仿真计算(3)完美高速型:4颗Xeon第三代处理器+最大内存带宽,与双xeon
3026
UltraLAB 2年前
新品上市-图灵超频工作站GT430M介绍 
整个机器在高频状态下,单核计算与多核并行计算、GPU超算、高速读写保证软件各个环节完美运行,可大幅缩短计算或处理时间,多核性能媲美双Xeon可扩展处理器架构硬件特点: 采用Intel Xeon W-3400超频处理器,单CPU最大核数56核@4.2GHz,三级缓存L3高达105MB,支持8个内存通道,其高主频、大缓存、大内存带宽特点,是目前单CPU多核并行算力的最强科学计算处理器。
2037
UltraLAB 3年前
结构/流体/多物理场/电磁仿真最快最完美工作站集群22v4
要点3 基于有限元分析法(结构仿真、流体仿真)的最快计算架构:CPU超高频+有限多核+高内存带宽,Alpha750机型是目前最快的仿真计算工作站。要点4 支持双子星架构(2台工作站通过Infiniband高速直连),最高核数达到224个,具有微型仿真集群的算力,计算效率更高,易于维护。
2111
UltraLAB 3年前
新型整车控制器关键技术分析 
多核芯片的算力与同频率单核芯片的算力加速比可以使用Amdahl定律来评估。公式如式(1):其中,S为多核芯片的算力与同频率单核芯片的算力加速比;a为并行计算部分所占的比例;n为核心数量。如图5,当并行程序为75%时,加速比的极限性能为4.0。在10核以内增加核心数都可以大幅提升运算性能。前期可以通过此方式对系统运算能力和分配要求做大略的评估,寻找一个最佳投入产出点。
3020 2 1
汽车公社 3年前
2023年人工智能训练与推理工作站、服务器、集群硬件配置推荐 
(四)支持A100+水冷---人工智能推理超级工作站硬件配置推荐 ---逻辑推理超算平台,支持8块A100+水冷静音级 完美计算架构:双xeon3代(最大80核),最大6块全速PCIe 4.0 16X全速 A100+海量存储(最大300T) 性能出众: FP16算力(8块RTX6000Ada)728Tflops,可以代替
3488
UltraLAB 3年前
【精彩回顾】远算与法电共同参加第十五届中国国际核电工业展览会 
远算基于该合作,结合HPC超算、云计算、CAE工业仿真等先进技术,研发了国产可控工业级仿真云平台、行业级专业仿真软件与核心设施数字孪生系统,已服务于能源、水利、环保、航空航天、汽车、高端装备等多个行业领域,满足工业4.0时代中国对工业仿真软件的特色需求。远算将不断深化与EDF的战略合作,继续深耕核电行业,共同助力核工业数字化转型。
2001
CAE璐姐 3年前
国内首款存算一体大算力芯片,瞄准智能驾驶! 
基于鸿途H30芯片后摩智能自主研发了一款软件开发工具链—后摩大道,支持 PyTorch、TensorFlow、ONNX等主流开源框架,编程兼容CUDA前端语法,同时支持SIMD和SIMT 两种编程模型,兼顾运行效率和开发效率,进一步实现了鸿途™H30 的高效、易用。 目前后摩智能的鸿途H30芯片将于6月份开始给Alpha客户送测。
4120 1 2
平头叔 3年前
PFC颗粒分析第一步:掌握离散元这些成样方法就够了! 
图6.2:GM法代码 图6.3:GM法过程中模型 图6.3:GM法结果模型可以发现这个方法生成的颗粒数比预想的要低,这是因为我这里颗粒数比较少,在生成的时候产生了较大的误差。到这里又熟悉了,想到了PFC中的Brick方法。
4618 11 4
lobby 4年前
新思科技携手台积公司全面加速EDA、IP及系统协同创新,助力下一代AI算力突破 
与此同时,新思科技在台积公司 N5、 N3P 和 N2P 制程上取得多项首次硅片成功(first-silicon)里程碑,包括 PCIe 7.0、HBM4、224G、DDR5 MRDIMM Gen2、LPDDR6/5X/5、UCIe 64G 以及 M‑PHY v6.0 IP,在性能、能效和可扩展性方面树立了全新领先水准。
1363
Ansys中国 16天前
20条/页 
 24
24 跳至页

技术邻APP
工程师必备
工程师必备
- 项目客服
- 培训客服
- 平台客服
TOP
