



abaqus6.14-1设置GPU并行计算的方法 
电脑配置:CPU i5-4590 (家里电脑是i7-6900k) 内存RAM 8G系统: win10 64位系统显卡低端GPU一个GTX650(公司的电脑,我家里配置的是GTX960)需要设置一下安装路径下的abaqus_v6.env的参数,没设置之前的参数如下,即使不成功,也方便返回原来设置。修改后的参数如下:好了,记得保存一下就行。
3695 84
琳泓comsol 7年前
ZEMAX软件技术应用专题:在薄膜計算中Ray以及Field系数是什麼? 
膜層被假設鍍在基板表面之前。正確計算光線的相位需要把電場逆向傳播到薄膜起始的位置,並且修正薄膜的相位計算方式為沿著光線方向,而不是表面法向量方向。Zemax OpticStudio把這些稱之為 “ray” 係數。因為光路徑長是沿著光線方向計算的,並且光線長度在薄膜中會隨著角度增加,因此光線的相位會以 1/cos(theta) 的變化方式近似,這樣才是增加膜層相位的光路徑長時,正確表示方式。
1939
w**elab86_Swsp 3年前
ZEMAX软件技术应用专题:在 OpticStudio 中模擬高階雷射光束 
但是,在此限制下,使用 Laguerre-Gaussian DLL 在 OpticStudio 中對這些模態進行建模在計算上更有效。隨著 e 接近 ∞,當由 Ince-Gaussian DLL 計算的特徵值解發散時,就會到達一個點。這種發散行為是計算算法的限制。當達到發散點時,Ince-Gaussian DLL 產生的結果變得不準確。
2057
w**elab86_Swsp 3年前
GPU引领CAE仿真算力革命 
强迫对流散热、液冷散热案例结果图Intel i7 8核并行与NVIDIA A4000单显卡案例运行时间及加速比结果对比 申请试用Simdroid-EC更多创新功能,敬请期待伏图6.0!
2425 1
仿真APP 1年前
ZEMAX软件技术应用专题:利用Kogelnik方法模擬體積全像光柵的繞射效率 
如果厚度從t到t'發生變化,則可以透過修改K∥計算出新的光柵向量,如方程式(4)。圖 4. 當全像材料收縮時,厚度從t 減少到 t'。我們現在已經介紹了體積全像圖模型的基礎知識。要了解有關如何在 OpticStudio 中應用該理論、如何設置序列和非序列系統以及下載範例系統的更多信息,您可以在此處取得本知識庫文章的全部內容。
2122
w**elab86_Swsp 3年前
支持192核+4块A100---2022年最强大AMD超算工作站GA660M上市 
尺寸:深度670mm,宽度400mm,高度565mm电源:2000w ,钛金,数量2个硬盘位:16个3.5”,2个5.25”PCI扩展槽:6个PCIe 4.0 16X,1个PCIe 4.0 8X前置端口:2个USB 3.0后置端口:2个万兆口,1个IPMI口,4个USB 3.2,3个USB 3.1 10 硬件系统优化
2708
UltraLAB 3年前
一文读懂Fluent并行计算,三大技术提升计算效率新境界! 
然而,对于分离式求解器,默认情况下并未使用GPU加速(即使在启动界面开启也没有效果),需要通过命令进行单独设置,具体操作步骤如下: 1.首先,在启动界面选择调用GPU的数量(根据电脑的实际配置进行选择)图6:Fluent启动界面 2.进入软件工作台界面后,在右侧命令端输入“/parallel/gpgpu/show”,即可显示当前使用的GPU型号,若GPU后方显示“*”,则表示
3976
神工坊(高性能仿真) 2年前
新品上市-图灵超频工作站GT430M介绍 
或蓝光DVD(刻录机) 9 平台 箱体:双塔式尺寸:深度658mm,宽度478mm,高度674mm电源:1600W/2000W,金牌,数量1~2个硬盘位:20个3.5”,2个5.25”PCI扩展槽:6*PCIe 4.0 x16,1*PCIe 4.0 x8后置端口:6个USB 3.2G2,2个万兆和2个千兆以太,8声道音频
2038
UltraLAB 3年前
云端解锁ParaView并行渲染,千万级网格模型可视化 
IceT是一个开源的并行图像合成库,主要用于 在大规模并行计算环境中可视化和渲染应用程序。IceT库提供了高效的并行渲染方法,适用于需要处理大规模数据集的可视化应用程序。ParaView通过库中sort-last算法进行并行渲染,算法将图像分割成多个小块,每个处理器都独立地渲染它所负责的块,并生成局部图像。然后,利用通信库(MPI)将这些局部图像组合起来,形成最终的合成图像。
2545
神工坊(高性能仿真) 11月前
智能驾驶域控制器SoC选型 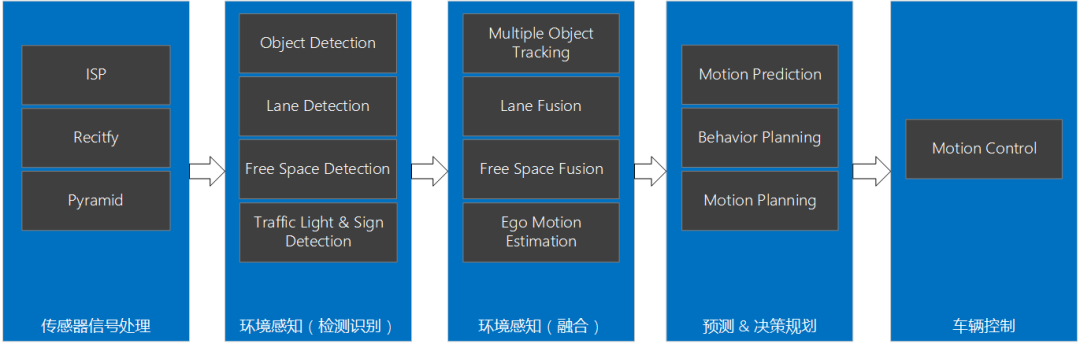
2.2 GPUCPU的功能模块多,适合复杂的运算场景,大部分晶体管用在控制电路和存储上,少部分用来完成运算工作。GPU的控制相对简单,且不需要很大的Cache,大部分晶体管被用于运算,GPU的计算速度因此大增,拥有强大的浮点运算能力。CPU与GPU架构对比示意图当前的多核CPU一般由4或6个核组成,以此模拟出8个或12个处理进程来运算。
2770
驾驶哥 3年前
有限元理论基础及Abaqus内部实现方式研究系列40: 梁单元差异(4)-形心、剪心和偏置 
1.4.1 算例2Example2:Ex2-TBeamNodeInShearCenter\我们还是以T型材的一个梁单元为例。先在iSolver中建模,为减少横向剪切刚度的影响,我们梁长度L取为240,仅取一个单元。 材料杨氏模量=1.5e6,泊松比=0.3。
5179 11 6
SnowWave02 3年前
CFD仿真 | 使用NVIDIA GPU加速仿真:本地部署和云解决方案 
// 热门活动推荐点播推荐:Ansys Fluent GPU solver 2025 R1新功能介绍Ansys Fluent原生GPU求解器致力于解决CFD方法在解决工程应用问题时,面临的计算效率问题,补充传统的基于CPU的计算资源难以满足高效计算的要求。
3186
Ansys中国 8月前
Ansys Zemax光学设计软件技术教程:眼科鏡片設計 
過去,Sultanova等人發表了 15種光學塑膠的折射率資料(參考資料2),每種材料都有8個波長的資料,並同時計算了每個材料的阿貝數 (V)。每個OpticStudio的眼科光學塑膠材料 (包含現在使用的這個) 都是先假設其色散曲線、折射率、阿貝數均與Sultanova的塑膠相似,接著利用Conrady公式,從NF、Nd、Ne及NC的數值中建立材料檔案。
2212
w**elab86_Swsp 3年前
一个方法快速完成动力学模拟计算 
md-gromacs.sh脚本的内容涵盖上述教程中的所有命令,根据北鲲云超算平台的指南需要在脚本开头加上导入gromacs模块,如果申请了GPU需要将GPU模块也导入(1-6行),具体脚本内容如下: 所有操作只需要可以登录北鲲云超算平台在线操作即可,无需自己配备高性能的计算机,和为繁琐的工具安装浪费时间。
2415
深圳北鲲云计算有限公司 3年前
ChatGPT服务器,深度拆解(2023) 
一般来说,通用服务器主要采用以CPU为主导的串行架构,更擅长逻辑运算;而AI服务器主要采用加速卡为主导的异构形式,更擅长做大吞吐量的并行计算。按CPU数量,通用服务器可分为双路、四路和八路等。虽然AI服务器一般仅搭载1-2块CPU,但GPU数量显著占优。按GPU数量,AI服务器可以分为四路、八路和十六路服务器,其中搭载8块GPU的八路AI服务器最常见。
2326 1 1
牛顿家的计算机 3年前
全面分析特斯拉机器人“超算”芯片(超越GPGPU?) 
特斯拉算力单元的层级划分 按照层次划分的话,每354个Dojo核心组成一块D1芯片,而每25颗芯片组成一个训练模组。最后120个训练模组组成一组ExaPOD计算集群,共计3000颗D1芯片。一个特斯拉Dojo芯片训练模组可以达到6组GPU服务器的性能,成本却少于单组GPU服务器。单台Dojo服务器算力甚至达到了54PFLOPS。
2736 1
牛顿家的计算机 3年前
在神工坊ParaView上体验并行渲染可视化 
IceT是一个开源的并行图像合成库,主要用于 在大规模并行计算环境中可视化和渲染应用程序。IceT库提供了高效的并行渲染方法,适用于需要处理大规模数据集的可视化应用程序。ParaView通过库中sort-last算法进行并行渲染,算法将图像分割成多个小块,每个处理器都独立地渲染它所负责的块,并生成局部图像。
2662
神工坊(高性能仿真) 2年前
CFD在心血管系统研究中的应用,速度较国外商软显著提升 
仿真性能对标国外S软件核并行时间自研GPU版1卡并行时间国外S软件在16核配置下仿真500步,耗时378s。相同的网格与模型配置下,采用VirtualFlow非结构求解器求解,在1块GPU显卡的情况下,同样计算500步,需要51s。可见自研非结构求解器的GPU版本计算效率是商软CPU计算的7~8倍。
2428 1 1
积鼎CFD流体仿真模拟 8月前
CFD在心血管系统研究中的应用,速度较国外商软显著提升
仿真性能对标国外S软件核并行时间自研GPU版1卡并行时间国外S软件在16核配置下仿真500步,耗时378s。相同的网格与模型配置下,采用VirtualFlow非结构求解器求解,在1块GPU显卡的情况下,同样计算500步,需要51s。可见自研非结构求解器的GPU版本计算效率是商软CPU计算的7~8倍。
2555 1 1
积鼎CFD流体仿真模拟 8月前
UNAT加速库:突破异构计算瓶颈,实现跨平台高效仿真 
目前,异构众核处理器的架构呈现出多样化的特点,涵盖了CPU+GPU架构、CPU+FPGA架构、CPU+ASIC架构、多核CPU架构以及国产申威架构等多种形式。与此同时,并行编程模型同样呈现多样化的趋势,包括用于GPU加速的CUDA、跨硬件的OpenCL、加速CPU和GPU的OpenACC、共享内存的OpenMP以及跨节点并行的MPI等编程语言。
2323 1
神工坊(高性能仿真) 2年前
20条/页 
 41
41 跳至页

技术邻APP
工程师必备
工程师必备
- 项目客服
- 培训客服
- 平台客服
TOP
